A probability matching problem


|
This post was updated on .
Hi all,
Now I am searching solutions for a problem. I have two datasets and want to create a new variables in dataset 2 by matching variables. But some of the variables are missing or wrong filled like presented in the picture. I want to find most probable match for my variable and assign the circled value to dataset 2. For instance in the picture, dataset 1 gives some variables define ''Apple''. In dataset 2, we have same variables but they are mistakenly wrong filled.(missing letters, wrong numbers etc.) Here, in data set 2, there is a new created variable last column. I want to assign the persons of dataset 1 into my new variable. It will be like ''assign the most probable person to dataset 2 by matching variables code, name, issue code... 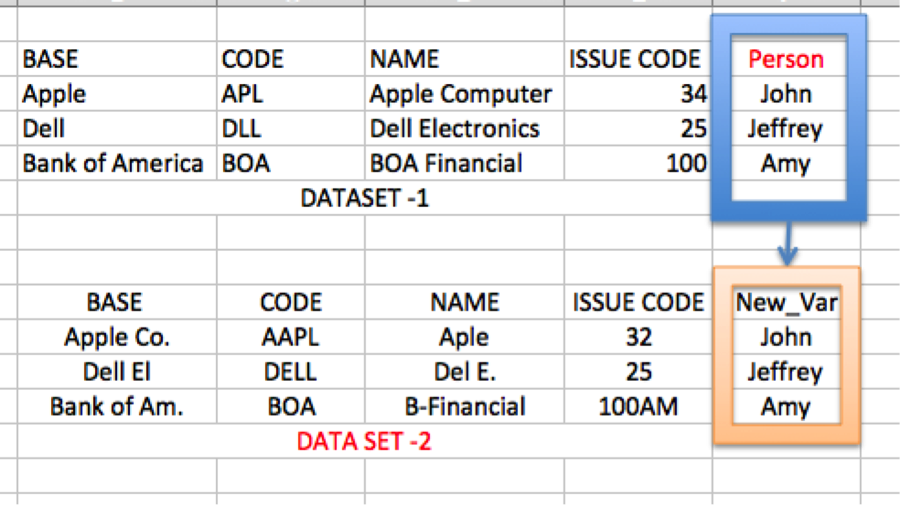
|
Re: A probability matching problem
|
Administrator
|
GIGO?
Abracadabra? --
Please reply to the list and not to my personal email.
Those desiring my consulting or training services please feel free to email me. --- "Nolite dare sanctum canibus neque mittatis margaritas vestras ante porcos ne forte conculcent eas pedibus suis." Cum es damnatorum possederunt porcos iens ut salire off sanguinum cliff in abyssum?" |

Re: A probability matching problem
|
|
In reply to this post by fevziesen
I am not sure I understand your post.
One thing it seems to say is that you have string variable that may be mistyped. You may have to go bacck and forth a few times to get a usable set of syn tax with a readable audit trail. Within a set you can use AUTORECODE and RECODE. then apply the template to the other set. use RECODE in the second set. when you are satisfied that content is consistently coded, you can do MATCH FILES or UPDATE or whatever would meet you ideas. paste the syntax below into the syntax window of a new instance of SPSS. Run it. Does this look like part of what you want? Does it help you post you query more clearly? DATA LIST LIST /FRUIT (a15). BEGIN DATA Apple apple APPLE aple pEAR PEAR peaR pair Peach Peech peach end data. autorecode variables= fruit /into Fruit## /save template = 'c:\project\autorecode demo template.sat' /print. recode fruit## (1,2,3,4=1)(5,8,9,10=2)(6,7,11=3) (else=-1)into Fruit#. value labels Fruit# 1 'Apple' 2 'Pear' 3 'Peach' -1 'oops check recode command'.
Art Kendall
Social Research Consultants |
Re: A probability matching problem
|
Administrator
|
Perhaps the following might stimulate some thoughts?
DATA LIST LIST/ a b c (3A3). BEGIN DATA ax b1 c1 xx bb cx yy bx cy END DATA. ALTER TYPE a b c (A20). COMPUTE @ID@=$CASENUM. DATASET NAME messy. VARSTOCASES /MAKE mess FROM a b c/INDEX=VARNAME(mess). SORT CASES BY varname mess. ALTER TYPE varname (A60). DATA LIST LIST / varname mess fixed (3a3). BEGIN DATA a ax a a xx x a yy y b b1 b b bb b2 b bx b3 c c1 c c cx c2 c cy c3 END DATA. SORT CASES BY varname mess fixed. ALTER TYPE mess fixed (A20). ALTER TYPE varname (A60). DATASET NAME bridge. MATCH FILES /FILE messy/TABLE * / BY varname mess. SORT CASES BY varname fixed. DATASET NAME bridged. SORT CASES BY @ID@ varname. CASESTOVARS ID=@ID@/INDEX=varname. RENAME VARIABLES (fixed.a fixed.b fixed.c= a b c). DATA LIST LIST/ a b c (3A3) name (A10). BEGIN DATA a b c John x b2 c2 Fred y b3 c3 Melissa END DATA. DATASET NAME canonical. ALTER TYPE a b c (A20). MATCH FILES FILE bridged / FILE * / BY a b c. EXECUTE.
Please reply to the list and not to my personal email.
Those desiring my consulting or training services please feel free to email me. --- "Nolite dare sanctum canibus neque mittatis margaritas vestras ante porcos ne forte conculcent eas pedibus suis." Cum es damnatorum possederunt porcos iens ut salire off sanguinum cliff in abyssum?" |
Re: A probability matching problem
|
|
In reply to this post by Art Kendall
It seems to me that the original post was
asking for the closest match in the two datasets using the string
variables as keys. It seems to me that this calls for a string similarity
metric similar to what is commonly used in spell checkers, although the
examples provided are challenging. A number of potentially appropriate
metrics are provided in the extendedTransforms.py module that could be
used with the SPSSINC TRANS extension command.
Potential metrics functions in that module include levenshteindistance, jaroWinkler, and DiceStringSimilarity. The Dicedict function is probably the easiest to use here and is set up for use with SPSSINC TRANS. There are also some metrics specific to names. Here is an example from that module. Note that this approach is not 1-1: a case from the second dataset might be the best match for more than one instance in the first. This requires, of course, the Python Essentials and the extendedTransforms.py module from the SPSS Community website (www.ibm.com/developerworks/spssdevcentral then Downloads for SPSS Statistics). * Use Dice to find closest match to the items in a dataset * using SPSSINC TRANS. *example: data list free/words(a10). begin data. 'Heard', 'Healthy', 'Help', 'Herded', 'Sealed', 'Sold', "Healed", '', 'heard', 'xyz' end data. dataset name words. data list list/asks(a9). begin data "heart" "Herded" "abc" "xyz" "helped" "help" end data. dataset name asks. exec. dataset activate asks. spssinc trans result=best type=10 /initial "extendedTransforms.Dicedict(wordds='words', stringsvar='words',casesensitive=False)" /formula "func(asks)". Jon Peck (no "h") aka Kim Senior Software Engineer, IBM [hidden email] phone: 720-342-5621 ===================== To manage your subscription to SPSSX-L, send a message to [hidden email] (not to SPSSX-L), with no body text except the command. To leave the list, send the command SIGNOFF SPSSX-L For a list of commands to manage subscriptions, send the command INFO REFCARD |
Re: A probability matching problem
|
|
In reply to this post by Art Kendall
What I see in the example is something that does not match the
=====================
To manage your subscription to SPSSX-L, send a message to
[hidden email] (not to SPSSX-L), with no body text except the
command. To leave the list, send the command
SIGNOFF SPSSX-L
For a list of commands to manage subscriptions, send the command
INFO REFCARD
description very well. [retrieved from Nabble; not yet on the List.] Original Post -- > For instance in the picture, dataset 1 gives some variables define ''Apple''. > In dataset 2, we have same variables but they are mistakenly wrong filled. > (missing letters, wrong numbers etc.) But the difference between a 3-letter code and a 4-letter code is not a matter of mis-spelling or randomly"missing letters"; it is the choice made by a corporation for an arbitrary, fixed code. I might wonder about misspelling for the longer version of the name, or differences in upper/lower case; however, also for that reason, I would concentrate on matching the codes that are all upper case, and would seem reliable that way. So: Match the ones that match perfectly; squeeze out the second vowel and match again; examine the results and see what algorithm suggests itself that would work on what is left. If there are merely hundreds of corporations, it would probably be fastest and most efficient to do the latter matching by human eyeball. -- Rich Ulrich > Date: Tue, 30 Dec 2014 07:40:47 -0700 > From: [hidden email] > Subject: Re: A probability matching problem > To: [hidden email] > > I am not sure I understand your post. > > One thing it seems to say is that you have string variable that may be > mistyped. [ ... ] > > View this message in context: http://spssx-discussion.1045642.n5.nabble.com/A-probability-matching-problem-tp5728290p5728297.html > Sent from the SPSSX Discussion mailing list archive at Nabble.com. > |
Re: A probability matching problem
|
Administrator
|
As is typical, an OP provides very little context for any sort of solution.
Where do these disparate data entry sources arise from? Is the coding within a specific data set consistent? How many categories exist within the universe of categories? Is this a one shot deal or an ongoing issue? Maybe a 'fuzzy matching' solution would work but I would be more confident with a 'bridge solution' of the sort I proposed earlier. If your data are consistently SLOPPY like this I would suggest educating your data venders or data entry people after establishing some STANDARDS!! ----
Please reply to the list and not to my personal email.
Those desiring my consulting or training services please feel free to email me. --- "Nolite dare sanctum canibus neque mittatis margaritas vestras ante porcos ne forte conculcent eas pedibus suis." Cum es damnatorum possederunt porcos iens ut salire off sanguinum cliff in abyssum?" |
|
|
If I miss you please correct me.
First I should convert the datasets into proper datasets and I need to have some standards. I mean I should have a corrected dataset. I mean if the company is ''Apple Electronics''legally, I need this dataset. But what if there are too many companies not defined correctly? In this case, I will need fuzzy matching that you said. I think variables are not too much important individually. We should assume the raws as a whole and match each dataset. I will try the solutions that are discussed above. |
«
Return to SPSSX Discussion
|
1 view|%1 views
| Free forum by Nabble | Edit this page |