|
|
Hello all,
I have a question to ask to you that I have been trying to solve for a while and it would be of great help if someone could give me advise on this.
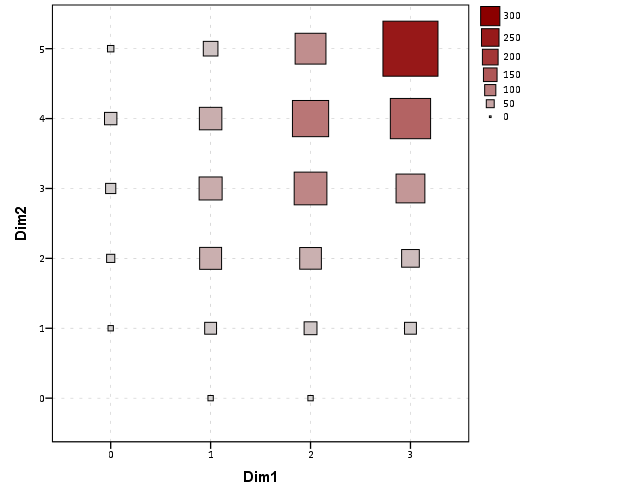
I want to make a scatterplot for my data, but because there are many overlapping data we decided to bin the values. This is the syntax that I used for the graph:
SOURSE: s=userSourse(id("Database1"))
DATA: Variable1=col(source(s), name("Variable1"))
DATA: Variable2=col(source(s), name("Variable2"))
GUIDE: axis(dim(1), label("Label1")
GUIDE: axis(dim(2), label("Label2")
SCALE: linear(dim(1), min(0), max(3), reverse())
SCALE: linear(dim(2), min(0), max(3), reverse())
ELEMENT: point(position(bin.rect(Variable1*Variable2, dim(1, 2))) , size(summery.count)))
The problem is that the scale of my scatterplot is "0.5 - 1.0 - 0.5 - 2.0 - 2.5". This does not correspond to the data, because if all the values in one bin would be counted, it could never be a half (but only whole numbers). I adjusted the binscale to the x-axis and y-axis but it did not solve the problem. Does anyone have a suggestion?
Thanks a lot !!!!
|