Deciphering from t test the mean


|
This post was updated on .
Hi,
Can someone help me as to why the mean is negative? How does the negative come about? Someone said that this would essentially indicate that there are no significant group differences with respect to these variables based on the data analyzed. I fed this into SPSS but what is the mathematics behind it? I mean how is this mean calculated when SPSS does this? I thought it is the total scores of say 1-SD, 2-D, 3- N, 4-A, 5-SA and divide that with the number of factors that I have with e.g. Conf Level Factor. Shouldnt this be positive? 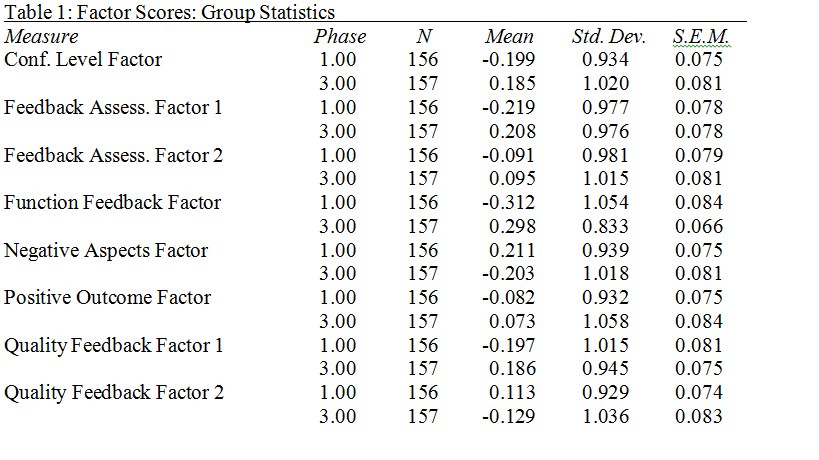
|
|
|
<http://spssx-discussion.1045642.n5.nabble.com/file/n5715820/image.png>
Sorry this is better. -- View this message in context: http://spssx-discussion.1045642.n5.nabble.com/Deciphering-from-t-test-the-mean-tp5715819p5715820.html Sent from the SPSSX Discussion mailing list archive at Nabble.com. ===================== To manage your subscription to SPSSX-L, send a message to [hidden email] (not to SPSSX-L), with no body text except the command. To leave the list, send the command SIGNOFF SPSSX-L For a list of commands to manage subscriptions, send the command INFO REFCARD |
Deriving Formula from Ordinal Regression Results to Classify New Cases?
|
|
In reply to this post by flint
What is the correct method for deriving a formula from the results of an Ordinal Regression, that can be used to predict the value of the dependent variable for new cases?
Thanks very much in advance to all for any info. Best, -Vik ===================== To manage your subscription to SPSSX-L, send a message to [hidden email] (not to SPSSX-L), with no body text except the command. To leave the list, send the command SIGNOFF SPSSX-L For a list of commands to manage subscriptions, send the command INFO REFCARD |
Re: Deciphering from t test the mean
|
Administrator
|
In reply to this post by flint
"Someone said"...
Be very very careful about listening to this "someone" person and you would do well to read up on your methodology notes? <clue stick tap> Factor scores have a pop mean of 0 and a Var of 1 and have nothing to do with group differences. </clue stick tap>
Please reply to the list and not to my personal email.
Those desiring my consulting or training services please feel free to email me. --- "Nolite dare sanctum canibus neque mittatis margaritas vestras ante porcos ne forte conculcent eas pedibus suis." Cum es damnatorum possederunt porcos iens ut salire off sanguinum cliff in abyssum?" |

Automatisk svar: Deciphering from t test the mean
|
|
Hi
I am not in the office right now - I will be back Friday November 1st and respond to your mail Best regards Søren |
Re: Deriving Formula from Ordinal Regression Results to Classify New Cases?
|
|
In reply to this post by Vik Rubenfeld
Dear Vik,
I guess if you figure out the structure of the formula (maybe "help" -> "algorithms" ?) we could insert the parameter estimates with Python (spssaux.GetValuesFromXMLWorkspace), thus completing your formula. However, "if it ain't broken...". So what's the problem with the standard approach? 1) add the new cases to the old ones 2) compute a weight variable, 1 for old cases, close to 0 (e.g. 1e-12) for new ones 3) if necessary, compute a valid value on the dependent variable for new cases 4) weight cases by weight variable 5) run analysis and save predicted values Including new cases in the analysis ensures they'll be given predicted values. However, the weighting procedure makes sure they won't have any effect on the parameter estimates (you'll see that these will be the same as for the old cases exclusively). Best, Ruben > Date: Tue, 23 Oct 2012 20:30:29 -0700 > From: [hidden email] > Subject: Deriving Formula from Ordinal Regression Results to Classify New Cases? > To: [hidden email] > > What is the correct method for deriving a formula from the results of an Ordinal Regression, that can be used to predict the value of the dependent variable for new cases? > > Thanks very much in advance to all for any info. > > Best, > > > -Vik > > ===================== > To manage your subscription to SPSSX-L, send a message to > [hidden email] (not to SPSSX-L), with no body text except the > command. To leave the list, send the command > SIGNOFF SPSSX-L > For a list of commands to manage subscriptions, send the command > INFO REFCARD |
Automatic reply: Deriving Formula from Ordinal Regression Results to Classify New Cases?
|
|
I will be out of the office from Wednesday, October 24th through Friday, October26th. I will respond to your e-mail when I return. Thanks! |
Re: Deriving Formula from Ordinal Regression Results to Classify New Cases?
|
|
In reply to this post by Ruben Geert van den Berg
<base href="x-msg://240/">
Hi Ruben, You were kind enough to bring this approach to my attention previously, and it was extremely useful in dividing the data into training and test data sets. Thanks very much! In this case, the client has requested an Excel spreadsheet, into which they can enter the values for the independent variables. The spreadsheet would then calculate the predicted value of the DV. So, I need to identify the correct formula. Best, -Vik On Oct 23, 2012, at 11:59 PM, Ruben van den Berg wrote:
|
Re: Deriving Formula from Ordinal Regression Results to Classify New Cases?
|
Administrator
|
In reply to this post by Vik Rubenfeld
@Vik and anyone/everyone else that this breach of netiquette applies to,
PLEASE BEGIN A *NEW* THREAD RATHER THAN CHANGING THE SUBJECT LINE ON SOMEONE ELSE'S TOPIC !!!!!
Please reply to the list and not to my personal email.
Those desiring my consulting or training services please feel free to email me. --- "Nolite dare sanctum canibus neque mittatis margaritas vestras ante porcos ne forte conculcent eas pedibus suis." Cum es damnatorum possederunt porcos iens ut salire off sanguinum cliff in abyssum?" |
|
|
In reply to this post by Vik Rubenfeld
Hi Vik,
I just did some similar work recently. Basically once you have output from an Ordinal Regression, write down the formula in Y= a+b1X1+b2X2+...you should know a and bi from your output. Then use this formula in your excel sheet as a simulation model in excel, with X1, X2...as independent variables for clients to enter. Y is the predicted value.
Hope this helps.
Clare From: SPSSX(r) Discussion on behalf of Vik Rubenfeld Sent: Tue 10/23/2012 8:30 PM To: [hidden email] Subject: Deriving Formula from Ordinal Regression Results to Classify New Cases? What is the correct method for deriving a formula from the results of an Ordinal Regression, that can be used to predict the value of the dependent variable for new cases? MailGate made the following annotations |
Re: Deriving Formula from Ordinal Regression Results to Classify New Cases?
|
|
In reply to this post by Vik Rubenfeld
I may be misunderstanding some things but … The “y” that is computed is the log odds. I’d think you want to know whether the probability of being in the comparison group is greater than 0.5. If so there are a couple of other computational steps. Gene Maguin From: SPSSX(r) Discussion [mailto:[hidden email]] On Behalf Of Yifan Lu Hi Vik, I just did some similar work recently. Basically once you have output from an Ordinal Regression, write down the formula in Y= a+b1X1+b2X2+...you should know a and bi from your output. Then use this formula in your excel sheet as a simulation model in excel, with X1, X2...as independent variables for clients to enter. Y is the predicted value. Hope this helps. Clare From: SPSSX(r) Discussion on behalf of Vik Rubenfeld What is the correct method for deriving a formula from the results of an Ordinal Regression, that can be used to predict the value of the dependent variable for new cases? MailGate made the following annotations |
Re: Deriving Formula from Ordinal Regression Results to Classify New Cases?
|
|
In reply to this post by David Marso
Hi David,
It was inadvertent. I started by replying to a recently received post via email. I removed the sender's email address and thought it was all good. I actually don't know how the threads are identified if not by subject line. Should I start a new thread and re-ask the question? Thanks for letting me know about this. Best, -Vik On Oct 24, 2012, at 5:01 AM, David Marso wrote: > @Vik and anyone/everyone else that this breach of netiquette applies to, > PLEASE BEGIN A **NEW* *THREAD RATHER THAN CHANGING THE SUBJECT LINE ON > SOMEONE ELSE'S TOPIC !!!!! > > Vik Rubenfeld wrote >> What is the correct method for deriving a formula from the results of an >> Ordinal Regression, that can be used to predict the value of the dependent >> variable for new cases? >> >> Thanks very much in advance to all for any info. >> >> Best, >> >> >> -Vik >> >> ===================== >> To manage your subscription to SPSSX-L, send a message to > >> LISTSERV@.UGA > >> (not to SPSSX-L), with no body text except the >> command. To leave the list, send the command >> SIGNOFF SPSSX-L >> For a list of commands to manage subscriptions, send the command >> INFO REFCARD > > > > > > ----- > Please reply to the list and not to my personal email. > Those desiring my consulting or training services please feel free to email me. > -- > View this message in context: http://spssx-discussion.1045642.n5.nabble.com/Deciphering-from-t-test-the-mean-tp5715819p5715833.html > Sent from the SPSSX Discussion mailing list archive at Nabble.com. > > ===================== > To manage your subscription to SPSSX-L, send a message to > [hidden email] (not to SPSSX-L), with no body text except the > command. To leave the list, send the command > SIGNOFF SPSSX-L > For a list of commands to manage subscriptions, send the command > INFO REFCARD ===================== To manage your subscription to SPSSX-L, send a message to [hidden email] (not to SPSSX-L), with no body text except the command. To leave the list, send the command SIGNOFF SPSSX-L For a list of commands to manage subscriptions, send the command INFO REFCARD |
Re: Deriving Formula from Ordinal Regression Results to Classify New Cases?
|
Administrator
|
No worries Vic:
If you go here you can see your post is threaded within a different topic when viewed through Nabble. http://spssx-discussion.1045642.n5.nabble.com/Deciphering-from-t-test-the-mean-td5715819.html Going here : http://spssx-discussion.1045642.n5.nabble.com/ there is a New Topic button. The reason why this is important are 3 or more fold ... 1. Your question gets buried under an irrelevant topic and people who might be willing and able to help won't see it. 2. The Original Poster of the initial topic has their question at the top but a bunch of irrelevant subthreads intermixed in their thread. 3. (My pet peeve): When responding to questions some people check the box to receive email when someone posts to the topic. Consequently anyone posting other questions and/or Out of Office Replies (another peeve - Wish the list would just filter them or ban people who only post OORs from posting-). This might be just idiosyncratic to Nabble archive but AFAIK it is really the best way to view them. The UGA interface is a complete joke (alphabetical order rather than by date and organized by month).. --
Please reply to the list and not to my personal email.
Those desiring my consulting or training services please feel free to email me. --- "Nolite dare sanctum canibus neque mittatis margaritas vestras ante porcos ne forte conculcent eas pedibus suis." Cum es damnatorum possederunt porcos iens ut salire off sanguinum cliff in abyssum?" |
Re: Deriving Formula from Ordinal Regression Results to Classify New Cases?
|
|
Thanks very much for this info, David. I will start a new thread and hope that those providing the great advice I am receiving will follow it.
Best, -Vik On Oct 24, 2012, at 10:53 AM, David Marso wrote: No worries Vic: |
|
|
In reply to this post by David Marso
Hi David
Appreciate this coz this is the 2nd time my post gets "ignored" because others were helping the other person. Anyway, glad you have pointed this out. Thanks. Flint |
|
|
In reply to this post by David Marso
Hi David,
Thank you. Will re look at the methodology. Lesson learnt never engage a statistician, I mean not all if I myself have no idea what I am doing. Flint |
Re: Deciphering from t test the mean
|
Administrator
|
To get the ball rolling... one reason why people may not be responding to your post is that you do not provide necessary info to respond. You present a table but do not tell us what it represents, how it was constructed, what it is supposed to tell you wrt to any hypotheses relevant to your study...So ...?
I'm not sure "never engage a statistician" is really the point. For some, engaging a statistician is on the same level of pain as consulting a plumber when your pipes get clogged, a dentist when your teeth hurt, a lawyer when you need justice... After all, you wouldn't try to extract your own bullet if you got shot? --
Please reply to the list and not to my personal email.
Those desiring my consulting or training services please feel free to email me. --- "Nolite dare sanctum canibus neque mittatis margaritas vestras ante porcos ne forte conculcent eas pedibus suis." Cum es damnatorum possederunt porcos iens ut salire off sanguinum cliff in abyssum?" |
Re: Deciphering from t test the mean
|
|
In reply to this post by flint
You have N=156 and N=157 for "Phase 1" and Phase 3", so it
*looks* like you have done this: You did a factoring on the combined set, and let SPSS score the factors. This incorporates every item into every factor, with a smaller or greater weight. The direction of the scale / factor is arbitrary technically -- observe the direction of the largest loadings to figure what direction the meaning is. (For useful scales, the usual practice in clinical work is to use a scoring rule: make a scale by creating the average item score for only the items that load above some cutoff, with the cutoff set at 0.35 or 0.40 or 0.45 or whatever, as needed in order to obtain a single factor for each variable to "belong to." Starting with "too many variables" you will get relatively large loadings.) What you have presented seems to be the means, etc., for the two phases that you started out with. As David mentioned, the overall mean for factor scored by the FA is 0.0, with variance of 1.0; that seems to be what your table shows, for data divided into two Phases. The differences between phases range from about 0.6, which is fairly large, to less than 0.2, which is fairly small (though a paired t-test will probably still show Phases as different). Since this is paired data, you would want a paired t-test to compare the two Phases properly. Possibly a majority of statisticians in the world have never done a factor analysis of any kind. They do teach it in departments of Education and Psychology. I hope it might be part of Biostatistics in Schools of Public Health these days, but it was not on the curriculum when I learned my formal statistics. I don't remember economists ever mentioning FA. What with "data mining", it ought to be taught more these days that it used to be, but I don't know whether it is. - This is in preparation to my saying, "You need a statistician who knows about this sort of statistics." I learned most of my data analysis by reading some excellent articles and a couple of textbooks while working on a job where I had an expert mentor on statistics; and then another job with expert mentor on experimental design. After a few years, I went back to school and picked up a background in formal theory, which was more useful than I had imagined it would be. In short: You don't know what you are doing? You won't create a decent job of it from throwing a stat-pack at the data unless you have pretty good feedback from a decent statistician who knows about the tools that you need. -- Rich Ulrich [table format revised, below] > Date: Tue, 23 Oct 2012 19:59:12 -0700 > From: [hidden email] > Subject: Deciphering from t test the mean > To: [hidden email] > > Hi, > Can someone help me as to why the mean is negative? How does the negative > come about? Someone said that this would essentially indicate that there are > no significant group differences with respect to these variables based on > the data analyzed. I fed this into SPSS but what is the mathematics behind > it? I mean how is this mean calculated when SPSS does this? I thought it is > the total scores of say 1-SD, 2-D, 3- N, 4-A, 5-SA and divide that with the > number of factors that I have with e.g. Conf Level Factor. Shouldnt this be > positive? > > Table 1: Factor Scores: Group Statistics > Measure Phase N Mean Std. Dev. S.E.M. 3.00 157 0.185 1.020 0.081 > Feedback Assess. Factor 1 1.00 156 -0.219 0.977 0.078 > 3.00 157 0.208 0.976 0.078 > Feedback Assess. Factor 2 1.00 156 -0.091 0.981 0.079 > 3.00 157 0.095 1.015 0.081 > > Thanks ... |
|
|
Hi Rich
Thanks for the explanation. It helps me to understand a little about this. I have something in mind when I did this. Of course can't do something without knowing why. Just had prob figuring out why it is negative. I guess I need to trace back the steps that I took to explain why the results are those. Thanks. Flint |
| Free forum by Nabble | Edit this page |