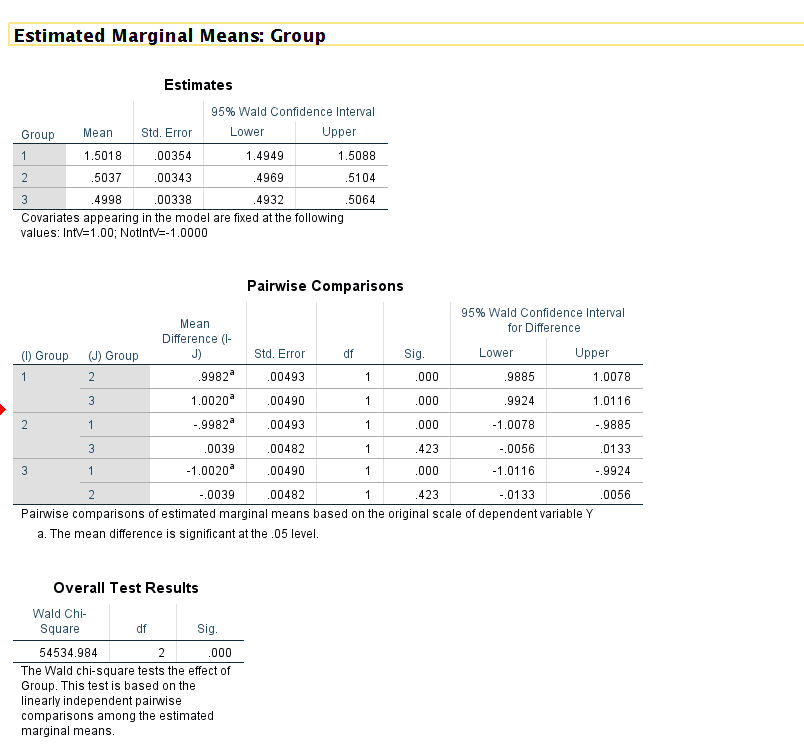
I did a simulation to show how I would do the contrasts for interactions with a binary treatment. It is kind of tricky to get SPSS to do them how I wanted. So here I simulate 3 groups, group 1 the treatment effect is 1.5, groups 2/3 the treatment effect is 0.5.
So you can see in the second GENLIN command is how to get the first order effects in the Estimates table. And then use the COMPARE keyword to test the differences in treatment effects between the groups (the Pairwise Comparisons table).
So this does a table for the differences between Group1InterventionEffect - Group2InterventionEffect, Group1InterventionEffect - Group3InterventionEffect, Group2InterventionEffect - Group3InterventionEffect, etc. Unfortunately SPSS shows redundant contrasts, but the final Wald test is the joint test of equality for all 3 tests (with 3 groups there are only 3 independent tests, so it is 2 degrees of freedom for the Chi-square stat).
*******************************************************.
*Simulated data.
DATASET CLOSE ALL.
OUTPUT CLOSE ALL.
SET SEED 10.
INPUT PROGRAM.
LOOP Id = 1 TO 10000.
END CASE.
END LOOP.
END FILE.
END INPUT PROGRAM.
* Intervention variable, need the obverse as well.
* To get SPSS to give me the contrast I want.
COMPUTE IntV = RV.BERNOULLI(0.5).
FORMATS IntV (F1.0).
RECODE IntV (1=0)(0=1) INTO NotIntV.
* 3 Different group variables.
COMPUTE Group = RV.UNIFORM(1,4).
COMPUTE Group = TRUNC(Group).
FORMATS Group (F1.0).
* Now the outcome varies by group.
DO IF Group = 1.
COMPUTE Y = 0.5 + 0.8 + 1.5*IntV + RV.NORMAL(0,0.1).
ELSE IF Group = 2.
COMPUTE Y = 0.5 + 0.2 + 0.5*IntV + RV.NORMAL(0,0.1).
ELSE IF Group = 3.
COMPUTE Y = 0.5 + 0.0 + 0.5*IntV + RV.NORMAL(0,0.1).
END IF.
EXECUTE.
* Here is the typical way people estimate the model and report coeff.
* Group 3 is the referent category.
GENLIN Y BY Group WITH IntV NotIntV
/MODEL Group IntV Group*IntV
DISTRIBUTION=NORMAL LINK=IDENTITY
/CRITERIA COVB=ROBUST.
* Here is how I would do the model to get the contrasts you want.
GENLIN Y BY Group WITH IntV NotIntV
/MODEL Group*IntV Group*NotIntV
DISTRIBUTION=NORMAL LINK=IDENTITY
INTERCEPT=NO
/CRITERIA COVB=ROBUST
/EMMEANS TABLES=Group CONTROL=IntV(1) NotIntV(-1) COMPARE=Group.
*******************************************************.