REPEATED MIXED MODELS-post hoc tests/contrasts


|
Hello!
I am studying the effect of trait anxiety on working memory efficiency (RT) and accuracy and I need some help with using LMM. The working memory task had four blocks varying in list length presentation, presented to each subject (1,2,3,4 words to recall). I was thinking to run a LMM with a random intercept with RT / ACC as a DV, list length as a repeated within factor (or covariate?), anxiety as a covariate. Therefore, I have the fixed effects: list length, anxiety and list length * anxiety interaction and at random effects, include intercept and Subjects (is that ok?) So I have the following variables: DV: efficiency score/ accuracy for every list length (continuous-within repeated measure) IV: list length (categorical) Covariate: trait anxiety (continuous) *each repeated measure (level 1) is within subject category (level 2). I already put the data in long format. My questions are: 1) in order for SPSS to know it's repeated data, should I choose from the first window of LMM, Subject ID at subjects and list length as a repeated measure? Or is it enough subjects and then include the random intercept? 2) how do I compare between list lengths? I want to show for example that list length’s effect is more significant at list length 4 that list length 1. So there are sign differences between lists. Should I use post hoc tests? Also, how do I compare which list length is more affected by it’s interaction with anxiety? Is there a contrast option in LMM for that? Thanks a lot! any kind of input would be very very helpful... Alexandra |
Re: REPEATED MIXED MODELS-post hoc tests/contrasts
|
|
I'm assuming that LMM means the Mixed command. I urge you to look in the Syntax Reference at Models 9 and 10 in the examples for Mixed. It's time to learn and use syntax. You don't say but if you measured anxiety once, i.e., trait anxiety, then Model 9 is a good example. If you measured anxiety, i.e., state anxiety, prior to each presentation, then Model 10 is a good example because anxiety is a time varying covariate.
With respect to the random intercept, I want to defer to others who are more experienced. That you have that anxiety covariate and are looking for a list-length by anxiety interaction is complicated. Perhaps you've done this already but I suggest plotting the DV by anxiety by list length to get an idea of where the interactions may exist. You also ought to save and plot the fixed predicted values (assuming no random effects) by anxiety and list length (and for the same reason). If there is an interaction, you need to identify what is called, I believe, "regions of significance". At least one person has written a macro for this and I don't recall who it is. I believe that you can iteratively identify the region boundaries using emmeans because you can iterate on covariate (i.e., anxiety) values and see the significance of the difference. The Test subcommand is more powerful but harder to use. Gene Maguin -----Original Message----- From: SPSSX(r) Discussion [mailto:[hidden email]] On Behalf Of Alexandra Sent: Monday, November 24, 2014 11:02 AM To: [hidden email] Subject: REPEATED MIXED MODELS-post hoc tests/contrasts Hello! I am studying the effect of trait anxiety on working memory efficiency (RT) and accuracy and I need some help with using LMM. The working memory task had four blocks varying in list length presentation, presented to each subject (1,2,3,4 words to recall). I was thinking to run a LMM with a random intercept with RT / ACC as a DV, list length as a repeated within factor (or covariate?), anxiety as a covariate. Therefore, I have the fixed effects: list length, anxiety and list length * anxiety interaction and at random effects, include intercept and Subjects (is that ok?) So I have the following variables: DV: efficiency score/ accuracy for every list length (continuous-within repeated measure) IV: list length (categorical) Covariate: trait anxiety (continuous) *each repeated measure (level 1) is within subject category (level 2). I already put the data in long format. My questions are: 1) in order for SPSS to know it's repeated data, should I choose from the first window of LMM, Subject ID at subjects and list length as a repeated measure? Or is it enough subjects and then include the random intercept? 2) * how do I compare between list lengths? I want to show for example that list length’s effect is more significant at list length 4 that list length 1. So there are sign differences between lists. Should I use post hoc tests? Also, how do I compare which list length is more affected by it’s interaction with anxiety? Is there a contrast option in LMM for that?* Thanks a lot! any kind of input would be very very helpful... Alexandra -- View this message in context: http://spssx-discussion.1045642.n5.nabble.com/REPEATED-MIXED-MODELS-post-hoc-tests-contrasts-tp5728007.html Sent from the SPSSX Discussion mailing list archive at Nabble.com. ===================== To manage your subscription to SPSSX-L, send a message to [hidden email] (not to SPSSX-L), with no body text except the command. To leave the list, send the command SIGNOFF SPSSX-L For a list of commands to manage subscriptions, send the command INFO REFCARD ===================== To manage your subscription to SPSSX-L, send a message to [hidden email] (not to SPSSX-L), with no body text except the command. To leave the list, send the command SIGNOFF SPSSX-L For a list of commands to manage subscriptions, send the command INFO REFCARD |
|
|
Thanks for your response. Trait anxiety was measured only once. I did a scatterplot on List length and Anxiety interaction. I attach the plot. You said I should make another plot with the fixed effect but not random effect and find the interaction where there are regions of significance....should I do then a different plot then the one attached? On Mon, Nov 24, 2014 at 8:11 PM, Maguin, Eugene [via SPSSX Discussion] <[hidden email]> wrote: I'm assuming that LMM means the Mixed command. I urge you to look in the Syntax Reference at Models 9 and 10 in the examples for Mixed. It's time to learn and use syntax. You don't say but if you measured anxiety once, i.e., trait anxiety, then Model 9 is a good example. If you measured anxiety, i.e., state anxiety, prior to each presentation, then Model 10 is a good example because anxiety is a time varying covariate. |
|
|
In reply to this post by Maguin, Eugene
Emmeans is used for contrasting between levels in the interaction of list length with anxiety? what about comparing the levels of list length before introducing the covariate?it's the same command? I know I should learn syntax but isn't there a simpler-menu driven approach to post hoc test and interaction contrasts untill I learn coding? I guess that would help for an entry level in SPSS....:D. If the anwer is yes, and there is a way, I still have the question if I should choose Subject as an ID in the first box of Linear mixed models command and list length as a repeated. Also, if I choose list length as a factor I get a fixed effects output that is similar to a paired t test...wouldn't that be a way to compare between levels of list length? Thanks a lot and sorry for so many questions:D PS: The syntax reference is the support material from SPSS? On Tue, Nov 25, 2014 at 12:26 AM, Alexandra Sabou <[hidden email]> wrote:
|
Re: REPEATED MIXED MODELS-post hoc tests/contrasts
|
|
In reply to this post by Alexandra
Attachments won’t pass through the list serv so the attachment wasn’t distributed although I think it will be able to be seen on nabble.
In the help dropdown you should see either “Syntax Reference” or “Command Syntax Reference” You’ve done the analysis it sounds like. Would you post the syntax and state what effects were significant. Gene Maguin From: SPSSX(r) Discussion [mailto:[hidden email]]
On Behalf Of Alexandra Thanks for your response. Trait anxiety was measured only once. I did a scatterplot on List length and Anxiety interaction. I attach the plot. You said I should make another plot with the fixed effect but not random effect and find the
interaction where there are regions of significance....should I do then a different plot then the one attached? On Mon, Nov 24, 2014 at 8:11 PM, Maguin, Eugene [via SPSSX Discussion] <[hidden email]> wrote:
View this message in context:
Re: REPEATED MIXED MODELS-post hoc tests/contrasts |
|
|
In reply to this post by Maguin, Eugene
 On Tue, Nov 25, 2014 at 12:36 AM, Alexandra Sabou <[hidden email]> wrote:
|
|
|
In reply to this post by Maguin, Eugene
hello! Sorry for the long pause. I found model 9 but don't see where can i fit the covariate-anxiety. Anxiety was measured only once. There's just LS which is the DV with the three repeated levels and Listlength that is a factor variable computed to separate the three levels. Spss data set is in long format: LS LISTLENGTH ID1 1223 1 ID1 1345 2 ID1 1567 3 This is the syntax from model 9 adapted for my variables: MIXED LS BY LISTLENGTH /FIXED = LISTLENGTH /REPEATED = LISTLENGTH | SUBJECT(SUBJECT_NAME) COVTYPE(CS). Results: LISTLENGTH effect-significant Where can I fit the covariate? Also, going back to the SPSS menu, should I keep Listlength as a factor or as a covariate? If I put it as a covariate then I can't use the EMMEANS command for post hoc tests. Also from the first window from mixed if I choose both Subject and repeated then is it correct to include an intercept also? I read that it is equivalent to use subjects + random intercept (without repeated variable) OR subject + repeated. Another important question: how can I test the interaction of the covariate (anxiety) for every level of LS variable? (ANXIETY* LISTLENGTH). It's obvious that with EMMEANS command I can only do posthocs for the factors includes as fixed effects NOT for interaction. I found a syntax for testing contrasts and interaction effects at ucla's site here but it's for a between factor (diet) with two levels and a repeated exercise type (exertype) with three levels. The Helmert coding is for comparing levels 1,2 vs level 3 of the rep variable but I would like something like a repeated contrast comparing every list level with the previous (there should be a liniar increase as I have the same memory measure with increasing difficulty) Mixed pulse by diet exertype time /fixed = diet exertype time diet*exertype /repeated = time | subject(id) covtype(ar1) /test = 'exertype 12v3 & diet 1v2' diet*exertype -.5 -.5 1 .5 .5 -1. On Tue, Nov 25, 2014 at 4:25 PM, Maguin, Eugene [via SPSSX Discussion] <[hidden email]> wrote:
|
|
|
In reply to this post by Maguin, Eugene
Also concerning the random intercept On Tue, Dec 2, 2014 at 3:22 PM, Alexandra Sabou <[hidden email]> wrote:
|
Re: REPEATED MIXED MODELS-post hoc tests/contrasts
|
|
In reply to this post by Alexandra
You began with data in wide format (something like):
id1 anxiety ls1 ls2 ls3. I know you are working on menus but the listing should show a varstocases command with these elements, although it may have others in addition. varstocases make ls from ls1 to ls3/index=listlength. The resulting file WILL have anxiety in it. Specifically the structure will be
Id1 anxiety listlength ls Your basic mixed command will have these elements
mixed ls by listlength with anxiety/fixed=listlength anxiety/repeated listlength | subject(id) covtype(cs). I looked at the menu and you will also get all the print subcommand options which are not shown in the above syntax. You are interested in the question of whether there is an interaction between listlength and anxiety, meaning that the regression homogeneity assumption is not
met. That syntax is mixed ls by listlength with anxiety/fixed=listlength anxiety listlength*anxiety /repeated listlength | subject(id) covtype(cs). Can you get your analysis down to this point and do the results make sense? Gene Maguin From: SPSSX(r) Discussion [mailto:[hidden email]]
On Behalf Of Alexandra hello! Sorry for the long pause. I found model 9 but don't see where can i fit the covariate-anxiety. Anxiety was measured only once. There's just LS which is the DV with the three repeated levels and Listlength that is a factor variable computed
to separate the three levels. Spss data set is in long format: LS LISTLENGTH ID1 1223 1 ID1 1345 2 ID1 1567 3 This is the syntax from model 9 adapted for my variables: MIXED LS BY LISTLENGTH /FIXED = LISTLENGTH /REPEATED = LISTLENGTH | SUBJECT(SUBJECT_NAME) COVTYPE(CS). Results: LISTLENGTH effect-significant Where can I fit the covariate? Also, going back to the SPSS menu, should I keep Listlength as a factor or as a covariate? If I put it as a covariate then I can't use the EMMEANS command for post hoc tests. Also from the first window
from mixed if I choose both Subject and repeated then is it correct to include an intercept also? I read that it is equivalent to use subjects + random intercept (without repeated variable) OR subject + repeated. Another important question: how can I test the interaction of the covariate (anxiety) for every level of LS variable? (ANXIETY* LISTLENGTH). It's obvious that with EMMEANS command I can only do posthocs for the factors includes as fixed
effects NOT for interaction. I found a syntax for testing contrasts and interaction effects at ucla's site here but it's for a between factor (diet) with two levels
and a repeated exercise type (exertype) with three levels. The Helmert coding is for comparing levels 1,2 vs level 3 of the rep variable but I would like something like a repeated contrast comparing every list level with the previous (there should be a liniar
increase as I have the same memory measure with increasing difficulty) Mixed pulse by diet exertype time /fixed = diet exertype time diet*exertype
/repeated = time | subject(id) covtype(ar1)
/test = 'exertype 12v3 & diet 1v2' diet*exertype -.5 -.5 1 .5 .5 -1. On Tue, Nov 25, 2014 at 4:25 PM, Maguin, Eugene [via SPSSX Discussion] <[hidden email]> wrote:
View this message in context:
Re: REPEATED MIXED MODELS-post hoc tests/contrasts |
|
|
Hello,
Yes, if I use the mixed menu command that would be the resulting output. Thatʹs the syntax I wrote directly, that‘s why there arentʹt any other specifications. With your syntax I did the analysis but with the unstructured covariance, MIXED LSRT BY LISTLENGTH gender WITH anx /CRITERIA=CIN(95) MXITER(100) MXSTEP(10) SCORING(1) SINGULAR(0.000000000001) HCONVERGE(0, ABSOLUTE) LCONVERGE(0, ABSOLUTE) PCONVERGE(0.000001, ABSOLUTE) /FIXED=LISTLENGTH gender anx LISTLENGTH*anx | SSTYPE(3) /METHOD=ML /PRINT=SOLUTION TESTCOV /RANDOM=INTERCEPT | SUBJECT(COD_subiect) COVTYPE(UN) /EMMEANS=TABLES(LISTLENGTH) COMPARE ADJ(BONFERRONI) /EMMEANS=TABLES(gender) COMPARE ADJ(BONFERRONI). The resulting output shows only sign anxiety effect and interaction, and with list length as a fixed factor I obtain an unsignificant result. Which unfortunately undermines the effect of the interaction because without a sign list length effect there isn't an explanation why the interaction is sign (only with harder list lengths anxiety will have a detrimental effect). However only when I add anxiety the effect of list length becomes insign. This is the output. Should I use a dummy variable for coding the three levels of list length (L1, L2,L3)? how should I interpret an interaction with three levels when LL3 x anx is set to zero? Parameter b SE t Sig. Intercept -25,5 297,8 -,086 ,932 [LISTLENGTH=1] 473,5 306,6 1,5 ,124 [LISTLENGTH=2] 597,2 306,7 1,9 ,053 [LISTLENGTH=3] 0a 0 . . [gender=1] 309.2 99.5 3.1 .002 [gender=2] 0a 0 . . anx 44,9 8.5 5.2 0.00 [LISTLENGTH=1] * anx -28,2 8,8 -3,1 ,002 [LISTLENGTH=2] * anx -25,6 8,8 -2,8 ,004 [LISTLENGTH=3] * anx 0a 0 . . a. This parameter is set to zero because it is redundant. b. Dependent Variable: LSRT. Thanks a lot again for all your help! Alexandra
On 12/2/14, Maguin, Eugene [via SPSSX Discussion] <[hidden email]> wrote: > > > You began with data in wide format (something like): > > id1 anxiety ls1 ls2 ls3. > > I know you are working on menus but the listing should show a varstocases > command with these elements, although it may have others in addition. > > varstocases make ls from ls1 to ls3/index=listlength. > > The resulting file WILL have anxiety in it. Specifically the structure will > be > > Id1 anxiety listlength ls > > Your basic mixed command will have these elements > > mixed ls by listlength with anxiety/fixed=listlength |
|
|
In reply to this post by Maguin, Eugene
To answer to the other question the database is already in wide format. This is the output for the restructure.
SAVE OUTFILE='C:\Users\Alexandra\Desktop\ls\LSS.sav' /COMPRESSED. VARSTOCASES /MAKE LSRT FROM LS_MEANRT1 LS_MEANRT2 LS_MEANRT3 /INDEX=LISTLENGTH(3) /KEEP=COD_subiect Trait_anxiety age_group gender /NULL=KEEP. Concerning the use of your previous suggested syntax (mixed ls by listlength with anxiety/fixed=listlength anxiety listlength*anxiety /repeated listlength | subject(id) covtype(cs), I changed it a bit in my previous e-mail from today but this would be the output from your syntax (the diff is in the cov type the fact that I used random intercept but in your syntax the repeated command mentioned LISTLENGTH-it's the same thing?) MIXED LSRT BY LISTLENGTH WITH Trait_anxiety /CRITERIA=CIN(95) MXITER(100) MXSTEP(10) SCORING(1) SINGULAR(0.000000000001) HCONVERGE(0, ABSOLUTE) LCONVERGE(0, ABSOLUTE) PCONVERGE(0.000001, ABSOLUTE) /FIXED=LISTLENGTH Trait_anxiety LISTLENGTH*Trait_anxiety | SSTYPE(3) /METHOD=ML /PRINT=SOLUTION TESTCOV /REPEATED=LISTLENGTH | SUBJECT(COD_subiect) COVTYPE(CS). Resulting output (without gender): Parameter b SE t Sig. Intercept 129,3 300,96 ,43 ,66 [LISTLENGTH=1] 455,5 307,3 1,48 ,14 [LISTLENGTH=2] 577,5 307,4 1,87 ,06 [LISTLENGTH=3] 0a 0 . . Trait_anxiety 44,28 8,71 5,08 ,000 [LISTLENGTH=1] * Trait_anxiety -27,75 8,89 -3,12 ,002 [LISTLENGTH=2] * Trait_anxiety -25,07 8,90 -2,81 ,005 [LISTLENGTH=3] * Trait_anxiety 0a 0 . . a. This parameter is set to zero because it is redundant. b. Dependent Variable: LSRT. I have the same question: how can I interpret this interaction? should I use dummy codes for three level within factor interaction (Listlength). Or what does the zero parameter from listlength 3 mean? |
Re: REPEATED MIXED MODELS-post hoc tests/contrasts
|
|
Alexandra, I am combining your two emails into one for replying
>>This is from your first email. The resulting output shows only sign anxiety effect and interaction, and with list length as a fixed factor I obtain an unsignificant result. Which unfortunately undermines the effect of the interaction because without a sign list length effect there isn't an explanation why the interaction is sign (only with harder list lengths anxiety will have a detrimental effect). However only when I add anxiety the effect of list length becomes insign. This is the output. Should I use a dummy variable for coding the three levels of list length (L1, L2,L3)? how should I interpret an interaction with three levels when LL3 x anx is set to zero? >> Your results (ignoring gender) are telling you that the relationship between anxiety and lsrt depends on listlength. You should see this if you compute the correlation between anxiety and lsrt within each listlength category. You would also see this if you plotted lsrt against anxiety by listlength and put a regression line in for each listlength category. Those regression lines will not be parallel. Furthermore, I think that the listlength-anxiety correlation is smaller and maybe nearly equal for listlength=1 and 2 because the b coefficients are similar. >>I strongly urge you to plot lsrt against anxiety by listlength because this plot will give you a visual understanding of what you have. You have a significant interaction between a categorical and a continuous variable. You are looking for what are called regions of significance. Those three regression lines cross (intersect) each other at some values of anxiety--three crosses, three values. From the crossing point for each pair of lines, there are two anxiety values, one to the right of the crossover point and one to the left, at which the difference between the two lines becomes significant. The important thing to understand is that the value at which the difference becomes significant does not have to be a possible anxiety scale score. >>Finding the significance values is basically algebra but that algebra involves computing the standard error of the difference. Do a google search or a PsychInfo search on "Johnson-Neyman" and "region of significance" (terms "or'ed" not "and'ed"). There's a number of articles but a recent and useful reference is Hayes, Andrew F.; Matthes, Jörg; Behavior Research Methods, Vol 41(3), Aug, 2009. pp.924-936. >>You can use the emmeans command to identify the boundary points by iteration. The command would be /EMMEANS=TABLES(LISTLENGTH) with (anxiety=>value<). >>Don't use a bonferroni adjustment because you are searching for a point rather than conducting a set of tests. As you know you can put a bunch of these emmeans commands in the command syntax so I'd look at the plots and pick a range of values and then iterate in. >>I think you could also use the Test subcommand; however, I don't directly know how to set that up. I'm sure others do and can offer specifics. I also want to acknowledge that I am unsure of whether there are additional issues or considerations because you are looking at the interaction of a covariate with a repeated factor. Again, I hope that if there are additional issues, a more knowledgeable reader will correct me and give you better advice. >>This is from your second email. I have the same question: how can I interpret this interaction? should I use dummy codes for three level within factor interaction (Listlength). Or what does the zero parameter from listlength 3 mean? >>The zero parameter for listlength 3 means that category was the reference category (this is standard and I've always been curious why that choice was made long ago). Notice that in your first analysis the same category was the reference category. The interpretation is the same as before: the anxiety-lsrt relationship differs across levels of listlength. Dummy codes won't do anything; they will be ignored. Gene Maguin -----Original Message----- From: SPSSX(r) Discussion [mailto:[hidden email]] On Behalf Of Alexandra Sent: Monday, December 29, 2014 7:48 AM To: [hidden email] Subject: Re: REPEATED MIXED MODELS-post hoc tests/contrasts To answer to the other question the database is already in wide format. This is the output for the restructure. SAVE OUTFILE='C:\Users\Alexandra\Desktop\ls\LSS.sav' /COMPRESSED. VARSTOCASES /MAKE LSRT FROM LS_MEANRT1 LS_MEANRT2 LS_MEANRT3 /INDEX=LISTLENGTH(3) /KEEP=COD_subiect Trait_anxiety age_group gender /NULL=KEEP. Concerning the use of your previous suggested syntax (mixed ls by listlength with anxiety/fixed=listlength anxiety listlength*anxiety /repeated listlength | subject(id) covtype(cs), I changed it a bit in my previous e-mail from today but this would be the output from your syntax (the diff is in the cov type the fact that I used random intercept but in your syntax the repeated command mentioned LISTLENGTH-it's the same thing?) MIXED LSRT BY LISTLENGTH WITH Trait_anxiety /CRITERIA=CIN(95) MXITER(100) MXSTEP(10) SCORING(1) SINGULAR(0.000000000001) HCONVERGE(0, ABSOLUTE) LCONVERGE(0, ABSOLUTE) PCONVERGE(0.000001, ABSOLUTE) /FIXED=LISTLENGTH Trait_anxiety LISTLENGTH*Trait_anxiety | SSTYPE(3) /METHOD=ML /PRINT=SOLUTION TESTCOV /REPEATED=LISTLENGTH | SUBJECT(COD_subiect) COVTYPE(CS). Resulting output (without gender): Parameter b SE t Sig. Intercept 129,3 300,96 ,43 ,66 [LISTLENGTH=1] 455,5 307,3 1,48 ,14 [LISTLENGTH=2] 577,5 307,4 1,87 ,06 [LISTLENGTH=3] 0a 0 . . Trait_anxiety 44,28 8,71 5,08 ,000 [LISTLENGTH=1] * Trait_anxiety -27,75 8,89 -3,12 ,002 [LISTLENGTH=2] * Trait_anxiety -25,07 8,90 -2,81 ,005 [LISTLENGTH=3] * Trait_anxiety 0a 0 . . a. This parameter is set to zero because it is redundant. b. Dependent Variable: LSRT. I have the same question: how can I interpret this interaction? should I use dummy codes for three level within factor interaction (Listlength). Or what does the zero parameter from listlength 3 mean? -- View this message in context: http://spssx-discussion.1045642.n5.nabble.com/REPEATED-MIXED-MODELS-post-hoc-tests-contrasts-tp5728007p5728293.html Sent from the SPSSX Discussion mailing list archive at Nabble.com. ===================== To manage your subscription to SPSSX-L, send a message to [hidden email] (not to SPSSX-L), with no body text except the command. To leave the list, send the command SIGNOFF SPSSX-L For a list of commands to manage subscriptions, send the command INFO REFCARD ===================== To manage your subscription to SPSSX-L, send a message to [hidden email] (not to SPSSX-L), with no body text except the command. To leave the list, send the command SIGNOFF SPSSX-L For a list of commands to manage subscriptions, send the command INFO REFCARD |
|
|
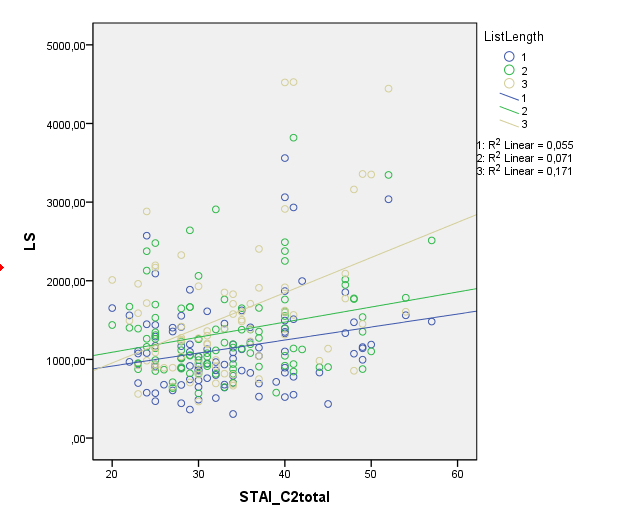
As you said, indeed the correlations between LSRT and anxiety in LL1 and LL2 are very similar, hence the plot shows almost parallel lines for these two list lengths. Only for LL3 the slope has a upward direction intersecting the regression lines for both LL2 and LL1.
You also said this: "I also want to acknowledge that I am unsure of whether there are additional issues or considerations because you are looking at the interaction of a covariate with a repeated factor." You wanted to mean that I shouldn't search for these points of significance because I am looking at the interaction of a covariate with a repeated factor that could as you mentioned : " not have to be a possible anxiety scale score. " I still tried to do what you recommended. So, in order to search for points of significance I should just look at the value at which there is an interaction between LL1-LL3 and LL2-LL3 and just write that value? for example if for the first interaction the plot shows an anxiety score between 10-20, I should just write the same command with every consecutive score from 10-20 and see when the mean is higher in LL3 compared to LL1? (that was obtained in the estimates of fixed effects-negative t result that shows a stronger relationship between anx-lsrt in the LL3 compared to LL1-is that correct???): /EMMEANS=TABLES(LISTLENGTH) with (Trait_anxiety=17). The first smallest anx value in this range where the mean of LL1 is smaller that LL3 is when anx has the value 17. Is this the value for the first sign anx-ls rt interaction (by LL1-LL3)? how should I interpret this result? should I state the confidence intervals and the mean Rt for every list length? For the second interaction (LL2-LL3) the smallest value of anx where the same relationship appears (LL2<LL3) is for the value of 24 in anx (supported by the plot). Every anx score beyond 24 leads to the same relationship L1<L2<L3 (LS RT means). I also have some questions concerning LLength. - When I run the LMM with List lenght as the repeated measure or only as a random slope, then the model does not acheive convergence. But when I use only a random intercept and subject combinations (random option), convergence is achieved. The resulting intercepts and betas from these models are slightly different, but they're all significant except for LLength's main effect. WITH REPEATED LLENGHT MIXED LSRT BY LISTLENGTH gender WITH Trait_anxiety /CRITERIA=CIN(95) MXITER(100) MXSTEP(10) SCORING(1) SINGULAR(0.000000000001) HCONVERGE(0, ABSOLUTE) LCONVERGE(0, ABSOLUTE) PCONVERGE(0.000001, ABSOLUTE) /FIXED=LISTLENGTH gender Trait_anxiety LISTLENGTH*Trait_anxiety | SSTYPE(3) /METHOD=ML /PRINT=SOLUTION TESTCOV /RANDOM=INTERCEPT | SUBJECT(COD_subiect) COVTYPE(UN) /REPEATED=LISTLENGTH | SUBJECT(COD_subiect) COVTYPE(UN). WITHOUT REPEATED LLENGTH (BUT LLENGTH RANDOM SLOPE) MIXED LSRT BY LISTLENGTH gender WITH Trait_anxiety /CRITERIA=CIN(95) MXITER(100) MXSTEP(10) SCORING(1) SINGULAR(0.000000000001) HCONVERGE(0, ABSOLUTE) LCONVERGE(0, ABSOLUTE) PCONVERGE(0.000001, ABSOLUTE) /FIXED=LISTLENGTH gender Trait_anxiety LISTLENGTH*Trait_anxiety | SSTYPE(3) /METHOD=ML /PRINT=SOLUTION TESTCOV /RANDOM=INTERCEPT LISTLENGTH | SUBJECT(COD_subiect) COVTYPE(UN) ONLY WITH RANDOM INTERCEPT MIXED LSRT BY LISTLENGTH gender WITH Trait_anxiety /CRITERIA=CIN(95) MXITER(100) MXSTEP(10) SCORING(1) SINGULAR(0.000000000001) HCONVERGE(0, ABSOLUTE) LCONVERGE(0, ABSOLUTE) PCONVERGE(0.000001, ABSOLUTE) /FIXED=LISTLENGTH gender Trait_anxiety LISTLENGTH*Trait_anxiety | SSTYPE(3) /METHOD=ML /PRINT=SOLUTION TESTCOV /RANDOM=INTERCEPT | SUBJECT(COD_subiect) COVTYPE(ID). 1) What's the difference between using LLength as REPEATED, RANDOM SLOPE or using just a random intercept with subject combinations? 2) I still wonder, does it make sense to look for the Llength-anx interaction when LLength's main effect becomes insignificant when I introduce the interaction in the model. Before using the interaction, Llength's effect is sign. |
Re: REPEATED MIXED MODELS-post hoc tests/contrasts
|
|
Replies embedded. From: SPSSX(r) Discussion [mailto:[hidden email]]
On Behalf Of Alexandra As you said, indeed the correlations between LSRT and anxiety in LL1 and LL2 are very similar, hence the plot shows almost parallel lines for these two list lengths. Only for LL3 the slope has a upward direction intersecting the regression
lines for both LL2 and LL1. You also said this: "I also want to acknowledge that I am unsure of whether there are additional issues or considerations because you are looking at the interaction of a covariate with a repeated factor." You wanted to mean that I shouldn't search for these points of significance because I am looking at the interaction of a covariate with a repeated factor that could as you mentioned : " not have to be a possible
anxiety scale score." >>What I meant was that I have seen the Johnson-Neyman method used for a regression equation having a between person dependent variable (DV). You have a within
person DV. It seems like it ought to work here as well. I have not read about using that method in this situation. I still tried to do what you recommended. So, in order to search for points of significance I should just look at the value at which there is an interaction between LL1-LL3 and LL2-LL3 and just write
that value? for example if for the first interaction the plot shows an anxiety score between 10-20, I should just write the same command with every consecutive score from 10-20 and see when the mean is higher in LL3 compared to LL1? (that was obtained in the
estimates of fixed effects-negative t result that shows a stronger relationship between anx-lsrt in the LL3 compared to LL1-is that correct???): /EMMEANS=TABLES(LISTLENGTH) with (Trait_anxiety=17). >>Yes, but you can be more efficient. Suppose the plot shows that LL1 and LL3 regression lines cross at about 6. Suppose the possible anxiety score range (mean
of items) is 1 to 7. Check whether the LL1-LL3 effect is significant for 1. If no, you’re done (do you know why?) If yes, check halfway between 1 and 6, 3.5, and so on.
The first smallest anx value in this range where the mean of LL1 is smaller that LL3 is when anx has the value 17. Is this the value for the first sign anx-ls rt interaction (by LL1-LL3)? how should I interpret this result? should I state
the confidence intervals and the mean Rt for every list length? For the second interaction (LL2-LL3) the smallest value of anx where the same relationship appears (LL2<LL3) is for the value of 24 in anx (supported by the plot). Every anx score beyond 24 leads to the same relationship L1<L2<L3 (LS RT
means). >>Not sure what you are telling me. Are you saying that when anxiety=17 or less, the LL1-LL3 difference is significant and when anxiety is greater than 17, say
18, the LL1-LL3 difference is not significant? >>And the LL2-LL3 difference was significant for anxiety GREATER THAN 24? Or was it significant for anxiety LESS THAN 24?
I also have some questions concerning LLength. - When I run the LMM with List lenght as the repeated measure or only as a random
slope, then the model does not acheive convergence. But when I use only a random intercept and subject combinations (random option), convergence is achieved. The resulting intercepts and betas from these models are slightly different, but they're all significant
except for LLength's main effect. >>I do not believe that this analysis statement is correct. You do not have a repeated factor and a random factor. I may be wrong but I think that the fact that
you are having convergence problems supports my assertion. WITH REPEATED LLENGHT MIXED LSRT BY LISTLENGTH gender WITH Trait_anxiety /CRITERIA=CIN(95) MXITER(100) MXSTEP(10) SCORING(1) SINGULAR(0.000000000001) HCONVERGE(0, ABSOLUTE) LCONVERGE(0, ABSOLUTE) PCONVERGE(0.000001, ABSOLUTE) /FIXED=LISTLENGTH gender Trait_anxiety LISTLENGTH*Trait_anxiety | SSTYPE(3) /METHOD=ML /PRINT=SOLUTION TESTCOV /RANDOM=INTERCEPT | SUBJECT(COD_subiect) COVTYPE(UN) /REPEATED=LISTLENGTH | SUBJECT(COD_subiect) COVTYPE(UN). WITHOUT REPEATED LLENGTH (BUT LLENGTH RANDOM SLOPE) MIXED LSRT BY LISTLENGTH gender WITH Trait_anxiety /CRITERIA=CIN(95) MXITER(100) MXSTEP(10) SCORING(1) SINGULAR(0.000000000001) HCONVERGE(0, ABSOLUTE) LCONVERGE(0, ABSOLUTE) PCONVERGE(0.000001, ABSOLUTE) /FIXED=LISTLENGTH gender Trait_anxiety LISTLENGTH*Trait_anxiety | SSTYPE(3) /METHOD=ML /PRINT=SOLUTION TESTCOV /RANDOM=INTERCEPT LISTLENGTH | SUBJECT(COD_subiect) COVTYPE(UN) ONLY WITH RANDOM INTERCEPT MIXED LSRT BY LISTLENGTH gender WITH Trait_anxiety /CRITERIA=CIN(95) MXITER(100) MXSTEP(10) SCORING(1) SINGULAR(0.000000000001) HCONVERGE(0, ABSOLUTE) LCONVERGE(0, ABSOLUTE) PCONVERGE(0.000001, ABSOLUTE) /FIXED=LISTLENGTH gender Trait_anxiety LISTLENGTH*Trait_anxiety | SSTYPE(3) /METHOD=ML /PRINT=SOLUTION TESTCOV /RANDOM=INTERCEPT | SUBJECT(COD_subiect) COVTYPE(ID). 1)
What's the difference between using LLength as REPEATED, RANDOM SLOPE or using just a random intercept with subject combinations? >>Basically, they are different was of constructing the analysis.
2) I still wonder, does it make sense to look for the Llength-anx interaction when LLength's main effect becomes insignificant when I introduce the interaction
in the model. Before using the interaction, Llength's effect is sign. Yes! Absolutely! Your result shows that reaction time depends on both list length and anxiety level. I’m guessing that lower anxiety predicts shorter reaction
times as the list length increases. Stated differently, anxiety may not matter much when the list is short but as the list lengthens higher anxiety impedes reaction time. Gene Maguin View this message in context:
Re: REPEATED MIXED MODELS-post hoc tests/contrasts |
|
|
Hello,
For LL1-LL3 the interaction is sign for anx score above 17, and for LL2-LL3 above 24. I don‘t think I get it why, based on your example with anx ranging from 1 to 7, if for 1 it‘s not sign then I shouldn‘t look further :D The only code that achieves convergence is the one with only the random intercept and without repeated list length or list length slope. I'll stick with this then... For the Johnson Neyman procedure I'll read more from the sources you recommended. Thanks a lot! On 12/31/14, Maguin, Eugene [via SPSSX Discussion] <[hidden email]> wrote: > > > Replies embedded. > > From: SPSSX(r) Discussion [mailto:[hidden email]] On Behalf Of > Alexandra > Sent: Tuesday, December 30, 2014 1:06 PM > To: [hidden email] > Subject: Re: REPEATED MIXED MODELS-post hoc tests/contrasts > > As you said, indeed the correlations between LSRT and anxiety in LL1 and LL2 > are very similar, hence the plot shows almost parallel lines for these two > list lengths. Only for LL3 the slope has a upward direction intersecting the > regression lines for both LL2 and LL1. > > You also said this: > "I also want to acknowledge that I am unsure of whether there are > |
Re: REPEATED MIXED MODELS-post hoc tests/contrasts
|
|
Is a score of 17 a valid score for your anxiety measure? I assumed you had averaged items and your items had a seven point response format. Thus scores would range between 1 and
7. Go back to the plot you made and mark in the possible anxiety score range. If 17 is inside of that range then an interaction makes sense. But suppose that the anxiety score range was 3 to 15. The highest score anybody could receive was 15. Would it make
sense to talk about an interaction that required a person to get a score of 17 or more?
=====================
To manage your subscription to SPSSX-L, send a message to
[hidden email] (not to SPSSX-L), with no body text except the
command. To leave the list, send the command
SIGNOFF SPSSX-L
For a list of commands to manage subscriptions, send the command
INFO REFCARD
Gene Maguin From: SPSSX(r) Discussion [[hidden email]] on behalf of Alexandra [[hidden email]]
Sent: Tuesday, January 06, 2015 3:46 PM To: [hidden email] Subject: Re: REPEATED MIXED MODELS-post hoc tests/contrasts Hello,
For LL1-LL3 the interaction is sign for anx score above 17, and for LL2-LL3 above 24. I don‘t think I get it why, based on your example with anx ranging from 1 to 7, if for 1 it‘s not sign then I shouldn‘t look further :D The only code that achieves convergence is the one with only the random intercept and without repeated list length or list length slope. I'll stick with this then... For the Johnson Neyman procedure I'll read more from the sources you recommended. Thanks a lot! On 12/31/14, Maguin, Eugene [via SPSSX Discussion] <[hidden email]> wrote: > > > Replies embedded. > > From: SPSSX(r) Discussion [mailto:[hidden email]] On Behalf Of > Alexandra > Sent: Tuesday, December 30, 2014 1:06 PM > To: [hidden email] > Subject: Re: REPEATED MIXED MODELS-post hoc tests/contrasts > > As you said, indeed the correlations between LSRT and anxiety in LL1 and LL2 > are very similar, hence the plot shows almost parallel lines for these two > list lengths. Only for LL3 the slope has a upward direction intersecting the > regression lines for both LL2 and LL1. > > You also said this: > "I also want to acknowledge that I am unsure of whether there are > View this message in context: Re: REPEATED MIXED MODELS-post hoc tests/contrasts Sent from the SPSSX Discussion mailing list archive at Nabble.com. ===================== To manage your subscription to SPSSX-L, send a message to [hidden email] (not to SPSSX-L), with no body text except the command. To leave the list, send the command SIGNOFF SPSSX-L For a list of commands to manage subscriptions, send the command INFO REFCARD |
|
|
I have not been paying close attention to this thread but I happened to read this post and thought I would add to what Gene mentioned. If the model includes a continuous IV ("x1"), categorical IV consisting of two groups ("x2"), and the interaction (x1*x2), then it typically makes sense to determine the shared range of both groups on x1, and estimate the mean difference on the DV between groups at various points across the shared range of x1 such as x1(1st quartile of shared range), x1(median of shared range), and x1(3rd quartile of shared range). By estimating the mean difference on the DV between groups at x1 values outside of the shared range, one is extrapolating beyond one or both groups, even if those values are possible. I tend to visualize cliffs as the lower (min value of the shared range) and upper (max value of the shared range) limits of the shared range and as I get closer to either cliff, the certainty of the estimated mean differences on the DV decreases, and beyond the cliffs is uncharted and potentially dangerous territory. HTH. Ryan
|
| Free forum by Nabble | Edit this page |