Using CSUM and LAG within groups and within time period

Using CSUM and LAG within groups and within time period

|
SPSS friends,
Given the following dataset (excluding the desired output column).
I want to calculate the cumulitive sum for each row using the Test_score variable and I want to do this within each id. That bit I have managed to solve, however to make things more complicated I only want to use those Test_Score values for each case from those taken from the preceeding 12 months. The desired output column shows you the output that I am trying to calculate. In essesence I am using CSUM within a group defined by ID and also within a time frame of the last 12 months.
I can work out the CSUM bit but not the lag for the preceeding 12 months.
sort cases by ID (A) date (A). split file by ID. create cum = CSUM(Test_Score). *but only use values for the last 12 months in the csum split file off.
Help - this is a tricky one (for me at least)
Many thanks,
Jack Thomas
|
Re: Using CSUM and LAG within groups and within time period
|
|
I tried to understand your post and tried some things. I do not
understand your meaning of what you want to include.
Copy the syntax below into a new instance of SPSS and see if it helps to clarify what you are asking. data list list/ ID (f1) score(f5.2) MyDate(date10) desire (f5.2). begin data 1 0.33 01.02.2007 0.33 1 0.50 20.03.2007 0.83 1 1.00 01.05.2008 1.00 1 1.00 15.05.2008 2.00 1 0.22 01.02.2008 2.22 1 0.22 20.03.2008 2.44 1 1.00 01.05.2008 3.44 1 1.00 15.05.2008 4.44 3 0.10 01.02.2006 0.10 3 0.33 20.03.2006 0.43 3 1.00 01.05.2006 1.43 3 0.98 15.05.2008 0.98 4 0.98 01.02.2008 0.98 4 0.77 02.03.2008 1.75 4 1.00 01.05.2010 1.00 end data. *sort cases by ID (A) mydate (A). compute seq = $casenum. formats seq (f3). match files file=* /keep seq all. split file by ID. create cum = CSUM(score). /*but only use values for the last 12 months in the csum. split file off. aggregate outfile=* mode=addvariables overwrite = yes /break = id /earliest = min(mydate) /latest = max(mydate). formats earliest latest(date10). compute gap1 = datediff(latest, mydate, "months"). if id eq lag(id) gap2 = datediff(mydate, lag(mydate), "months"). formats gap1 gap2 (f4). sort cases by seq(d). compute gap3 = datediff(mydate, earliest, "months"). formats gap3 (f4). sort cases by seq (a). if gap1 le 12 use1=score. if gap2 le 12 use2=score. if gap3 le 12 use3=score. split file by id. create try1 = CSUM(use1) /try2 = CSUM(use2) /try3 = CSUM(use3). split file off. list. Art Kendall Social Research Consultants On 12/4/2010 1:47 PM, Snuffy Dog wrote: ===================== To manage your subscription to SPSSX-L, send a message to [hidden email] (not to SPSSX-L), with no body text except the command. To leave the list, send the command SIGNOFF SPSSX-L For a list of commands to manage subscriptions, send the command INFO REFCARD
Art Kendall
Social Research Consultants |
Re: Using CSUM and LAG within groups and within time period
|
Administrator
|
In reply to this post by Snuffy Dog
Hey Dawg,
Here is another way to do this. Restructure the data from long to wide and then use vectors. Finally restructure from wide to long. Modify the index values appropriately (8 change to the largest number of values per id). BTW: Several of your data values are out of order, so your "desire" column is incorrect. OR maybe you should have ID as 2. Anyway, my solution should do the trick. 1 1.00 15.05.2008 2.00 1 0.22 01.02.2008 2.22 ---------------------------------------------------------------------------------------------------- DATA LIST LIST/ ID (f1) score(f5.2) MyDate(date10) desire (f5.2). BEGIN DATA 1 0.33 01.02.2007 0.33 1 0.50 20.03.2007 0.83 1 1.00 01.05.2008 1.00 1 1.00 15.05.2008 2.00 1 0.22 01.02.2008 2.22 1 0.22 20.03.2008 2.44 1 1.00 01.05.2008 3.44 1 1.00 15.05.2008 4.44 3 0.10 01.02.2006 0.10 3 0.33 20.03.2006 0.43 3 1.00 01.05.2006 1.43 3 0.98 15.05.2008 0.98 4 0.98 01.02.2008 0.98 4 0.77 02.03.2008 1.75 4 1.00 01.05.2010 1.00 END DATA. SORT CASES BY id mydate. IF $CASENUM=1 OR (ID NE lag(ID)) SEQ=1. IF SYSMIS(SEQ) SEQ=LAG(SEQ)+1. VECTOR DATES(8) SCORES(8). COMPUTE DATES(SEQ)=mydate. COMPUTE SCORES(SEQ)=score. AGGREGATE OUTFILE * / BREAK ID / DATES1 TO DATES8 SCORES1 TO SCORES8 =MAX(DATES1 TO DATES8 SCORES1 TO SCORES8). FORMATS DATES1 TO DATES8 (EDATE). VECTOR DATES=DATES1 TO DATES8 . VECTOR SCORES=SCORES1 TO SCORES8. VECTOR CUMS(8). LOOP #=1 TO 8. + COMPUTE CUMS(#)=0. + LOOP ##=# TO 1 BY -1. + IF CTIME.DAYS(DATES(#)-DATES(##)) LE 365.25 CUMS(#)=CUMS(#) + SCORES(##). + END LOOP. END LOOP. LOOP #=1 to 8. + COMPUTE SCORE=SCORES(#). + COMPUTE MYDATE=DATES(#). + COMPUTE CUM=CUMS(#). + DO IF NOT MISSING(SCORE). + XSAVE OUTFILE "TMP.SAV" / KEEP ID SCORE MYDATE CUM. + END IF. END LOOP. EXE. GET FILE "TMP.SAV" . ------------------------------------------------------ Another version using CASESTOVARS and VARSTOCASES. The core is identical. DATA LIST LIST/ ID (f1) score(f5.2) MyDate(date10) desire (f5.2). BEGIN DATA 1 0.33 01.02.2007 0.33 1 0.50 20.03.2007 0.83 1 1.00 01.05.2008 1.00 1 1.00 15.05.2008 2.00 1 0.22 01.02.2008 2.22 1 0.22 20.03.2008 2.44 1 1.00 01.05.2008 3.44 1 1.00 15.05.2008 4.44 3 0.10 01.02.2006 0.10 3 0.33 20.03.2006 0.43 3 1.00 01.05.2006 1.43 3 0.98 15.05.2008 0.98 4 0.98 01.02.2008 0.98 4 0.77 02.03.2008 1.75 4 1.00 01.05.2010 1.00 END DATA. SORT CASES BY id mydate. IF $CASENUM=1 OR (ID NE lag(ID)) SEQ=1. IF SYSMIS(SEQ) SEQ=LAG(SEQ)+1. FORMATS SEQ(F2.0). CASESTOVARS /ID = id /INDEX = seq /GROUPBY = VARIABLE . VECTOR DATES=MYDATE.1 TO MYDATE.8 . VECTOR SCORES=SCORE.1 TO SCORE.8. VECTOR CUMS(8). LOOP #=1 TO 8. + COMPUTE CUMS(#)=0. + LOOP ##=# TO 1 BY -1. + IF CTIME.DAYS(DATES(#)-DATES(##)) LE 365.25 CUMS(#)=CUMS(#) + SCORES(##). + END LOOP. END LOOP. VARSTOCASES /MAKE mydate FROM mydate.1 TO mydate.8 /MAKE Score FROM score.1 TO score.8 /MAKE cum FROM cums1 TO cums8 /KEEP = id /NULL = DROP. SELECT IF NOT MISSING(SCORE). LIST. ID MYDATE SCORE CUM 1 01-FEB-07 .33 .33 1 20-MAR-07 .50 .83 1 01-FEB-08 .22 1.05 1 20-MAR-08 .22 .44 1 01-MAY-08 1.00 1.44 1 01-MAY-08 1.00 2.44 1 15-MAY-08 1.00 3.44 1 15-MAY-08 1.00 4.44 3 01-FEB-06 .10 .10 3 20-MAR-06 .33 .43 3 01-MAY-06 1.00 1.43 3 15-MAY-08 .98 .98 4 01-FEB-08 .98 .98 4 02-MAR-08 .77 1.75 4 01-MAY-10 1.00 1.00 Number of cases read: 15 Number of cases listed: 15
Please reply to the list and not to my personal email.
Those desiring my consulting or training services please feel free to email me. --- "Nolite dare sanctum canibus neque mittatis margaritas vestras ante porcos ne forte conculcent eas pedibus suis." Cum es damnatorum possederunt porcos iens ut salire off sanguinum cliff in abyssum?" |
|
|
In reply to this post by Snuffy Dog
Hi Jack,
Here is a simple solution. If you need more definite date differences then you can change 12 month to 365 days. sc : sum of score for each id during last 12 months.  SORT CASES BY id(A) date(A). compute sc =score. DO IF ($casenum =1 | id > lag(id)). compute sc = score. ELSE if (id = lag(id) & (DATEDIFF(date,lag(date),'month') < 12)) . compute sc = sum(lag(sc), score). END IF. EXECUTE. Max. |
|
|
Then output result is as follows:
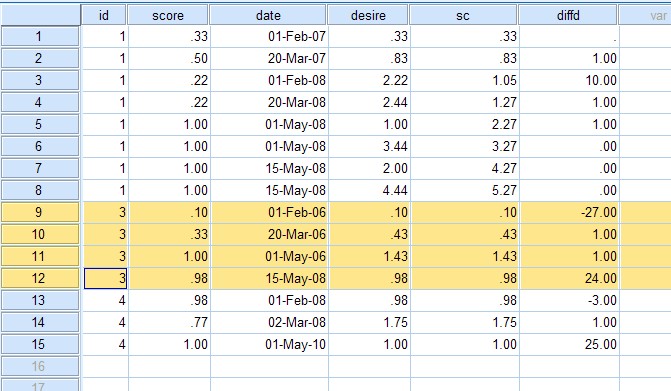 Your desire values are different because you did not sort cases by id & date. |
Re: Using CSUM and LAG within groups and within time period
|
Administrator
|
Nice try, but... Sorry, wrong answer!
OP req was that the cum be windowed within one year, not that consecutive values be within 1 year. I suspect that the simplest solution is what I previously posted.
Please reply to the list and not to my personal email.
Those desiring my consulting or training services please feel free to email me. --- "Nolite dare sanctum canibus neque mittatis margaritas vestras ante porcos ne forte conculcent eas pedibus suis." Cum es damnatorum possederunt porcos iens ut salire off sanguinum cliff in abyssum?" |
Re: Using CSUM and LAG within groups and within time period
|
|
In reply to this post by David Marso
Hi all,
Supplimental question. David's solution works best however what I neglected to add was that the maximum number of rows per ID grouping variable may change and in some cases goes into the hundreds. Currently the solution uses 8 vectors, is there an automatic way to work out the the maximum number of vectors required and write the program to dynamically reflect this?
Kind regard,
Jack
On Sun, Dec 5, 2010 at 12:22 PM, David Marso <[hidden email]> wrote: Hey Dawg, |
Re: Using CSUM and LAG within groups and within time period
|
|
Here is a solution using programmability
with no constraints on the number of records or long to wide conversion.
It uses the SPSSINC TRANS extension command available from SPSS Developer Central. For simplicity, it is using a nominal 365-day year, but it could be made to use exact calendar differences with a little more work. It wasn't clear to me whether to include a score from exactly 12 months ago. In the test data, based on the desired output values, I excluded such a value, but by changing the "<" in the comparison to "<=" it would work the other way. I can send the program off-line if the email messes up the indentation below. data list free/ID(F2.0) Test_Score(F8.2) Date(EDATE10) Desired_output.(F8.2). begin data 1 0.33 01.02.2007 0.33 1 0.50 20.03.2007 0.83 1 1.00 01.05.2008 1.00 1 1.00 15.05.2008 2.00 1 0.22 01.02.2008 2.22 1 0.22 20.03.2008 2.44 1 1.00 01.05.2008 3.44 1 1.00 15.05.2008 4.44 3 0.10 01.02.2006 0.10 3 0.33 20.03.2006 0.43 3 1.00 01.05.2006 1.43 3 0.98 15.05.2008 0.98 4 0.98 01.02.2008 0.98 4 0.77 02.03.2008 1.75 4 1.00 01.05.2010 1.00 end data. exec. * This program will be called for each case. begin program. import spss, sys nominalyear = 365*24*60*60 def csum(ID, Test_Score, Date): global history, previd if not hasattr (sys.modules[__name__], "previd") or ID != previd: previd = ID history = set() history.add((Date, Test_Score)) print history thecsum = 0 for item in history: if Date - item[0] < nominalyear: thecsum += item[1] return thecsum end program. SPSSINC TRANS result=csum /FORMULA csum(ID, Test_Score, Date). HTH, Jon Peck Senior Software Engineer, IBM [hidden email] 312-651-3435 From: Snuffy Dog <[hidden email]> To: [hidden email] Date: 12/05/2010 05:20 AM Subject: Re: [SPSSX-L] Using CSUM and LAG within groups and within time period Sent by: "SPSSX(r) Discussion" <[hidden email]> Hi all, Supplimental question. David's solution works best however what I neglected to add was that the maximum number of rows per ID grouping variable may change and in some cases goes into the hundreds. Currently the solution uses 8 vectors, is there an automatic way to work out the the maximum number of vectors required and write the program to dynamically reflect this? Kind regard, Jack On Sun, Dec 5, 2010 at 12:22 PM, David Marso <david.marso@...> wrote: Hey Dawg, Here is another way to do this. Restructure the data from long to wide and then use vectors. Finally restructure from wide to long. Modify the index values appropriately (8 change to the largest number of values per id). BTW: Several of your data values are out of order, so your "desire" column is incorrect. OR maybe you should have ID as 2. Anyway, my solution should do the trick. 1 1.00 15.05.2008 2.00 1 0.22 01.02.2008 2.22 ---------------------------------------------------------------------------------------------------- DATA LIST LIST/ ID (f1) score(f5.2) MyDate(date10) desire (f5.2). BEGIN DATA 1 0.33 01.02.2007 0.33 1 0.50 20.03.2007 0.83 1 1.00 01.05.2008 1.00 1 1.00 15.05.2008 2.00 1 0.22 01.02.2008 2.22 1 0.22 20.03.2008 2.44 1 1.00 01.05.2008 3.44 1 1.00 15.05.2008 4.44 3 0.10 01.02.2006 0.10 3 0.33 20.03.2006 0.43 3 1.00 01.05.2006 1.43 3 0.98 15.05.2008 0.98 4 0.98 01.02.2008 0.98 4 0.77 02.03.2008 1.75 4 1.00 01.05.2010 1.00 END DATA. SORT CASES BY id mydate. IF $CASENUM=1 OR (ID NE lag(ID)) SEQ=1. IF SYSMIS(SEQ) SEQ=LAG(SEQ)+1. VECTOR DATES(8) SCORES(8). COMPUTE DATES(SEQ)=mydate. COMPUTE SCORES(SEQ)=score. AGGREGATE OUTFILE * / BREAK ID / DATES1 TO DATES8 SCORES1 TO SCORES8 =MAX(DATES1 TO DATES8 SCORES1 TO SCORES8). FORMATS DATES1 TO DATES8 (EDATE). VECTOR DATES=DATES1 TO DATES8 . VECTOR SCORES=SCORES1 TO SCORES8. VECTOR CUMS(8). LOOP #=1 TO 8. + COMPUTE CUMS(#)=0. + LOOP ##=# TO 1 BY -1. + IF CTIME.DAYS(DATES(#)-DATES(##)) LE 365.25 CUMS(#)=CUMS(#) + SCORES(##). + END LOOP. END LOOP. LOOP #=1 to 8. + COMPUTE SCORE=SCORES(#). + COMPUTE MYDATE=DATES(#). + COMPUTE CUM=CUMS(#). + DO IF NOT MISSING(SCORE). + XSAVE OUTFILE "TMP.SAV" / KEEP ID SCORE MYDATE CUM. + END IF. END LOOP. EXE. GET FILE "TMP.SAV" . ------------------------------------------------------ Another version using CASESTOVARS and VARSTOCASES. The core is identical. DATA LIST LIST/ ID (f1) score(f5.2) MyDate(date10) desire (f5.2). BEGIN DATA 1 0.33 01.02.2007 0.33 1 0.50 20.03.2007 0.83 1 1.00 01.05.2008 1.00 1 1.00 15.05.2008 2.00 1 0.22 01.02.2008 2.22 1 0.22 20.03.2008 2.44 1 1.00 01.05.2008 3.44 1 1.00 15.05.2008 4.44 3 0.10 01.02.2006 0.10 3 0.33 20.03.2006 0.43 3 1.00 01.05.2006 1.43 3 0.98 15.05.2008 0.98 4 0.98 01.02.2008 0.98 4 0.77 02.03.2008 1.75 4 1.00 01.05.2010 1.00 END DATA. SORT CASES BY id mydate. IF $CASENUM=1 OR (ID NE lag(ID)) SEQ=1. IF SYSMIS(SEQ) SEQ=LAG(SEQ)+1. FORMATS SEQ(F2.0). CASESTOVARS /ID = id /INDEX = seq /GROUPBY = VARIABLE . VECTOR DATES=MYDATE.1 TO MYDATE.8 . VECTOR SCORES=SCORE.1 TO SCORE.8. VECTOR CUMS(8). LOOP #=1 TO 8. + COMPUTE CUMS(#)=0. + LOOP ##=# TO 1 BY -1. + IF CTIME.DAYS(DATES(#)-DATES(##)) LE 365.25 CUMS(#)=CUMS(#) + SCORES(##). + END LOOP. END LOOP. VARSTOCASES /MAKE mydate FROM mydate.1 TO mydate.8 /MAKE Score FROM score.1 TO score.8 /MAKE cum FROM cums1 TO cums8 /KEEP = id /NULL = DROP. SELECT IF NOT MISSING(SCORE). LIST. ID MYDATE SCORE CUM 1 01-FEB-07 .33 .33 1 20-MAR-07 .50 .83 1 01-FEB-08 .22 1.05 1 20-MAR-08 .22 .44 1 01-MAY-08 1.00 1.44 1 01-MAY-08 1.00 2.44 1 15-MAY-08 1.00 3.44 1 15-MAY-08 1.00 4.44 3 01-FEB-06 .10 .10 3 20-MAR-06 .33 .43 3 01-MAY-06 1.00 1.43 3 15-MAY-08 .98 .98 4 01-FEB-08 .98 .98 4 02-MAR-08 .77 1.75 4 01-MAY-10 1.00 1.00 Number of cases read: 15 Number of cases listed: 15 Snuffy Dog wrote: > > SPSS friends, > > Given the following dataset (excluding the desired output column). > > I want to calculate the cumulitive sum for each row using the Test_score > variable and I want to do this within each id. That bit I have managed to > solve, however to make things more complicated I only want to use those > Test_Score values for each case from those taken from the preceeding 12 > months. The desired output column shows you the output that I am trying to > calculate. In essesence I am using CSUM within a group defined by ID and > also within a time frame of the last 12 months. > > I can work out the CSUM bit but not the lag for the preceeding 12 months. > > sort cases by ID (A) date (A). > split file by ID. > create cum = CSUM(Test_Score). *but only use values for the last 12 months > in the csum > split file off. > > ID Test_Score Date Desired_output 1 0.33 01.02.2007 0.33 1 0.50 > 20.03.2007 0.83 1 1.00 01.05.2008 1.00 1 1.00 15.05.2008 2.00 1 0.22 > 01.02.2008 2.22 1 0.22 20.03.2008 2.44 1 1.00 01.05.2008 3.44 1 1.00 > 15.05.2008 4.44 3 0.10 01.02.2006 0.10 3 0.33 20.03.2006 0.43 3 1.00 > 01.05.2006 1.43 3 0.98 15.05.2008 0.98 4 0.98 01.02.2008 0.98 4 0.77 > 02.03.2008 1.75 4 1.00 01.05.2010 1.00 > > Help - this is a tricky one (for me at least) > > Many thanks, > > Jack Thomas > > -- View this message in context: http://spssx-discussion.1045642.n5.nabble.com/Using-CSUM-and-LAG-within-groups-and-within-time-period-tp3292384p3292649.html Sent from the SPSSX Discussion mailing list archive at Nabble.com. ===================== To manage your subscription to SPSSX-L, send a message to LISTSERV@... (not to SPSSX-L), with no body text except the command. To leave the list, send the command SIGNOFF SPSSX-L For a list of commands to manage subscriptions, send the command INFO REFCARD |
Re: Using CSUM and LAG within groups and within time period
|
|
Ok I worked out my Python integration was faulty and this is now fixed.
Jon your solution works well except that is does not sum scores within the same ID that have the same date. Note for example that I have two dates ( 01-05-2008 and 15-05-2008) which are duplicated over two rows within the ID=1 group. The program is only taking one score per date where I need it to take a score from each date.
On Mon, Dec 6, 2010 at 5:13 AM, Snuffy Dog <[hidden email]> wrote:
|
Re: Using CSUM and LAG within groups and within time period
|
|
Thank you Jon that worked perfectly.
I did work on a numpty solution to the duplicate date problem by creating a dequence counter within each group and then adding this as a time seconds value to the date variable so that each date was unquie by at least 1 second but your solution is so much better -
Thank you very much for your help, I am both grateful and impressed.
Jack
On Mon, Dec 6, 2010 at 8:17 AM, Jon K Peck <[hidden email]> wrote: I didn't realize that you could have more than one instance on the same date. This variation should deal with that. |
Re: Using CSUM and LAG within groups and within time period
|
|
Oh bummer - when using the example data file for this problem the solution worked fine but when using my whole data set I encounter the following error:
Error: The formula references an undefined variable or could not be evaluated:
name 'Date' is not defined Thoughts?
On Mon, Dec 6, 2010 at 8:22 AM, Snuffy Dog <[hidden email]> wrote:
|
Re: Using CSUM and LAG within groups and within time period
|
|
Really? Ok I made the variable names match on case and now it works
Thank You so Much!!!!!!!!!
On Mon, Dec 6, 2010 at 9:58 AM, Jon K Peck <[hidden email]> wrote: Does the case match? While variable name case does not matter in Statistics, it does matter here. |
Re: Using CSUM and LAG within groups and within time period
|
|
In reply to this post by Snuffy Dog
Shalom
Here is another way to handle that challenge . The program need only one pass of the data and loop only on the necessary part of the vector . Hillel Vardi BGU DATA LIST LIST/ ID (f1) score(f5.2) Date(date10) desire (f5.2). BEGIN DATA 1 0.33 01.02.2007 0.33 1 0.50 20.03.2007 0.83 1 1.00 01.05.2008 1.00 1 1.00 15.05.2008 2.00 1 0.22 01.02.2008 2.22 1 0.22 20.03.2008 2.44 1 1.00 01.05.2008 3.44 1 1.00 15.05.2008 4.44 3 0.10 01.02.2006 0.10 3 0.33 20.03.2006 0.43 3 1.00 01.05.2006 1.43 3 0.98 15.05.2008 0.98 4 0.98 01.02.2008 0.98 4 0.77 02.03.2008 1.75 4 1.00 01.05.2010 1.00 END DATA. SORT CASES BY id(A) date(A). add files file = * / by id/first=first. if first eq 1 seq=0. if first eq 1 run=1 . compute seq=sum(seq,1). leave seq run . VECTOR #DATES(8) #SCORES(8). compute #DATES(seq) =date . compute #SCORES(seq) =SCORE . loop ii=run to seq . do if DATEDIFF(#DATES(seq) ,#DATES(ii),"days") gt 365 . compute run=sum(run,1) . else . compute sumscore=sum(sumscore,#SCORES(ii) ) . end if . end loop . EXECUTE. add files file =* / keep=ID score Date seq sumscore . SPSS friends, > > Given the following dataset (excluding the desired output column). > > I want to calculate the cumulitive sum for each row using the Test_score > variable and I want to do this within each id. That bit I have managed to > solve, however to make things more complicated I only want to use those > Test_Score values for each case from those taken from the preceeding 12 > months. The desired output column shows you the output that I am trying to > calculate. In essesence I am using CSUM within a group defined by ID and > also within a time frame of the last 12 months. > > I can work out the CSUM bit but not the lag for the preceeding 12 months. > > sort cases by ID (A) date (A). > split file by ID. > create cum = CSUM(Test_Score). *but only use values for the last 12 months > in the csum > split file off. > > ID Test_Score Date Desired_output 1 0.33 01.02.2007 0.33 1 0.50 > 20.03.2007 0.83 1 1.00 01.05.2008 1.00 1 1.00 15.05.2008 2.00 1 0.22 > 01.02.2008 2.22 1 0.22 20.03.2008 2.44 1 1.00 01.05.2008 3.44 1 1.00 > 15.05.2008 4.44 3 0.10 01.02.2006 0.10 3 0.33 20.03.2006 0.43 3 1.00 > 01.05.2006 1.43 3 0.98 15.05.2008 0.98 4 0.98 01.02.2008 0.98 4 0.77 > 02.03.2008 1.75 4 1.00 01.05.2010 1.00 > > Help - this is a tricky one (for me at least) > > Many thanks, > > Jack Thomas > > ===================== To manage your subscription to SPSSX-L, send a message to [hidden email] (not to SPSSX-L), with no body text except the command. To leave the list, send the command SIGNOFF SPSSX-L For a list of commands to manage subscriptions, send the command INFO REFCARD |
Re: Using CSUM and LAG within groups and within time period
|
|
In reply to this post by Snuffy Dog
At 01:47 PM 12/4/2010, Snuffy Dog wrote:
>I want to calculate the cumulative sum of the Test_score variable >within each id. However, I only want to use those Test_Score values >for each case from those taken from the preceeding 12 months. > >Help - this is a tricky one (for me at least) As you've seen, it's a fairly tricky one altogether, though you've also received some good solutions. As an exercise and illustration, here's a solution using long-form data organization and native SPSS code. Like Jon Peck's Python solution, it should have no constraints on the number of records per ID. It performs the summing loop once -- I think the Python code runs the loop for each case -- and so *might* have speed advantages on very large files. In this solution, 'year' is taken as calendar year. |-----------------------------|---------------------------| |Output Created |07-DEC-2010 22:13:02 | |-----------------------------|---------------------------| [TestData] ID Test_Score Date 1 .33 01.02.2007 1 .50 20.03.2007 1 .22 01.02.2008 1 .22 20.03.2008 1 1.00 01.05.2008 1 1.00 01.05.2008 1 1.00 15.05.2008 1 1.00 15.05.2008 3 .10 01.02.2006 3 .33 20.03.2006 3 1.00 01.05.2006 3 .98 15.05.2008 4 .98 01.02.2008 4 .77 02.03.2008 4 1.00 01.05.2010 Number of cases read: 15 Number of cases listed: 15 DATASET COPY CumNow. DATASET ACTIVATE CumNow WINDOW=Front. split file by ID. CREATE ToDate = CSUM(Test_Score). Create |-----------------------------|---------------------------| |Output Created |07-DEC-2010 22:13:03 | |-----------------------------|---------------------------| [CumNow] Created Series |--|-|------|--------------------|----------|----------------| |ID| |Series|Case Number of |N of Valid|Creating | | | |Name |Non-Missing Values |Cases |Function | | | | |---------------|----| | | | | | |First |Last| | | |--|-|------|--------------------|----------|----------------| |1 |1|ToDate| 1 | 8 |8 |CSUM(Test_Score)| |3 |1|ToDate| 9 |12 |4 |CSUM(Test_Score)| |4 |1|ToDate|13 |15 |3 |CSUM(Test_Score)| |--|-|------|--------------------|----------|----------------| FORMATS ToDate (F5.2). VAR LABEL ToDate 'Total score thru current date'. split file off. DATASET COPY CumPast. DATASET ACTIVATE CumPast WINDOW=Front. COMPUTE Date = DATESUM(Date, 1, "years"). VAR LABEL ToDate 'Total score thru one year ago'. EXECUTE /* needed because of a glitch in dataset handling */. ADD FILES /FILE=CumPast /RENAME=(ToDate Test_Score =To1yrAgo drop1 ) /FILE=CumNow /BY ID Date /DROP=drop1 /KEEP=ID Test_Score Date ToDate To1yrAgo. IF (MISSING(To1yrAgo) AND ID EQ LAG(ID)) To1yrAgo=LAG(To1yrAgo). RECODE To1yrAgo (MISSING=0). EXECUTE /* so the LAG calculation is completed before the selection */. SELECT IF NOT MISSING(Test_Score). COMPUTE InPastYr = ToDate - To1yrAgo. FORMATS InPastYr (F5.2). LIST. List |-----------------------------|---------------------------| |Output Created |07-DEC-2010 22:13:06 | |-----------------------------|---------------------------| ID Test_Score Date ToDate To1yrAgo InPastYr 1 .33 01.02.2007 .33 .00 .33 1 .50 20.03.2007 .83 .00 .83 1 .22 01.02.2008 1.05 .33 .72 1 .22 20.03.2008 1.27 .83 .44 1 1.00 01.05.2008 2.27 .83 1.44 1 1.00 01.05.2008 3.27 .83 2.44 1 1.00 15.05.2008 4.27 .83 3.44 1 1.00 15.05.2008 5.27 .83 4.44 3 .10 01.02.2006 .10 .00 .10 3 .33 20.03.2006 .43 .00 .43 3 1.00 01.05.2006 1.43 .00 1.43 3 .98 15.05.2008 2.41 1.43 .98 4 .98 01.02.2008 .98 .00 .98 4 .77 02.03.2008 1.75 .00 1.75 4 1.00 01.05.2010 2.75 1.75 1.00 Number of cases read: 15 Number of cases listed: 15 ============================= APPENDIX: Test data, and code ============================= DATA LIST LIST/ ID Test_Score Date #Desired (F2,F5.2, EDATE10, F5.2). BEGIN DATA 1 0.33 01.02.2007 0.33 1 0.50 20.03.2007 0.83 1 1.00 01.05.2008 1.00 1 1.00 15.05.2008 2.00 1 0.22 01.02.2008 2.22 1 0.22 20.03.2008 2.44 1 1.00 01.05.2008 3.44 1 1.00 15.05.2008 4.44 3 0.10 01.02.2006 0.10 3 0.33 20.03.2006 0.43 3 1.00 01.05.2006 1.43 3 0.98 15.05.2008 0.98 4 0.98 01.02.2008 0.98 4 0.77 02.03.2008 1.75 4 1.00 01.05.2010 1.00 END DATA. DATASET NAME TestData WINDOW=FRONT. SORT CASES BY ID Date. LIST. DATASET COPY CumNow. DATASET ACTIVATE CumNow WINDOW=Front. split file by ID. CREATE ToDate = CSUM(Test_Score). FORMATS ToDate (F5.2). VAR LABEL ToDate 'Total score thru current date'. split file off. DATASET COPY CumPast. DATASET ACTIVATE CumPast WINDOW=Front. COMPUTE Date = DATESUM(Date, 1, "years"). VAR LABEL ToDate 'Total score thru one year ago'. EXECUTE /* needed because of a glitch in dataset handling */. ADD FILES /FILE=CumPast /RENAME=(ToDate Test_Score =To1yrAgo drop1 ) /FILE=CumNow /BY ID Date /DROP=drop1 /KEEP=ID Test_Score Date ToDate To1yrAgo. IF (MISSING(To1yrAgo) AND ID EQ LAG(ID)) To1yrAgo=LAG(To1yrAgo). RECODE To1yrAgo (MISSING=0). EXECUTE /* so the LAG calculation is completed before the selection */. SELECT IF NOT MISSING(Test_Score). COMPUTE InPastYr = ToDate - To1yrAgo. FORMATS InPastYr (F5.2). LIST. ===================== To manage your subscription to SPSSX-L, send a message to [hidden email] (not to SPSSX-L), with no body text except the command. To leave the list, send the command SIGNOFF SPSSX-L For a list of commands to manage subscriptions, send the command INFO REFCARD |
| Free forum by Nabble | Edit this page |