2 histogram side by side


Banned User
|
How to make something like this.
I know how to make separate histograms but how to make it together? 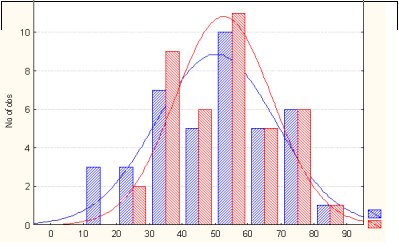
|
Re: 2 histogram side by side
|
|
I think the most simple way to do this is using ggplot2 (R).
Frans 2013/7/24 markecb <[hidden email]> How to make something like this. |
|
Banned User
|
I must admit that for a long time I have not worked with the R program
 is there a way to do it in SPSS or tutorial for R ggplot2? is there a way to do it in SPSS or tutorial for R ggplot2?
|
Re: 2 histogram side by side
|
|
In reply to this post by markecb
Everyone:
Pasted below is what may be a better way to present multiple histograms, using R and more specifically the lattice package. Of course, there are many other ways to approach this challenge, but lattice is often a first consideration for this type of presentation. Please let me know if you need more context for the dataset (GenRegM1M2.df) and additional R-based syntax. Best wishes. Tom > ls() [1] "GenRegM1M2.df" > str(GenRegM1M2.df) 'data.frame': 30 obs. of 6 variables: $ Subject : Factor w/ 30 levels "1","2","3","4",..: 1 2 3 4 5 6 7 8 9 10 ... $ Gender : int 1 1 1 1 1 1 1 1 1 1 ... $ Region : Factor w/ 2 levels "North","South": 1 2 1 1 1 2 2 1 2 1 ... $ M1 : num 89 81 92 94 74 56 77 85 78 69 ... $ M2 : num 1.72 1.24 1.79 1.69 1.73 1.35 1.25 1.81 1.61 1.71 ... $ Gender.recode: Factor w/ 2 levels "Female","Male": 1 1 1 1 1 1 1 1 1 1 ... > head(GenRegM1M2.df) Subject Gender Region M1 M2 Gender.recode 1 1 1 North 89 1.72 Female 2 2 1 South 81 1.24 Female 3 3 1 North 92 1.79 Female 4 4 1 North 94 1.69 Female 5 5 1 North 74 1.73 Female 6 6 1 South 56 1.35 Female > summary(GenRegM1M2.df) Subject Gender Region M1 M2 Gender.recode 1 : 1 Min. :1.0 North:14 Min. :45.00 Min. :1.090 Female:15 2 : 1 1st Qu.:1.0 South:16 1st Qu.:80.25 1st Qu.:1.272 Male :15 3 : 1 Median :1.5 Median :86.50 Median :1.620 4 : 1 Mean :1.5 Mean :83.23 Mean :1.525 5 : 1 3rd Qu.:2.0 3rd Qu.:91.00 3rd Qu.:1.730 6 : 1 Max. :2.0 Max. :97.00 Max. :1.810 (Other):24 > > install.packages("lattice") > library(lattice) # Load the lattice package. > help(package=lattice) # Show the information page. > sessionInfo() # Confirm all attached packages. R version 2.15.2 (2012-10-26) Platform: i386-w64-mingw32/i386 (32-bit) locale: [1] LC_COLLATE=English_United States.1252 LC_CTYPE=English_United States.1252 LC_MONETARY=English_United States.1252 LC_NUMERIC=C [5] LC_TIME=English_United States.1252 attached base packages: [1] stats graphics grDevices utils datasets methods base other attached packages: [1] lattice_0.20-15 loaded via a namespace (and not attached): [1] grid_2.15.2 tools_2.15.2 > par(ask=TRUE) # 1 Column by 1 Row Density Plot > lattice::densityplot(~ GenRegM1M2.df$M1, + type="count", # Note: count + par.settings=simpleTheme(lwd=2), + par.strip.text=list(cex=1.15, font=2), + scales=list(cex=1.15), + main="Density Plot of M1", + xlab=list("M1", cex=1.15, font=2), + xlim=c(0,120), # Note the range. + ylab=list("Density", cex=1.15, font=2), + aspect=1, + layout = c(1,1), # Note: 1 Column by 1 Row. + col="red") Waiting to confirm page change... > > par(ask=TRUE) # 1 Column by 2 Rows Density Plot > lattice::densityplot(~ GenRegM1M2.df$M1 | + GenRegM1M2.df$Gender.recode, + type="count", # Note: count + par.settings=simpleTheme(lwd=2), + par.strip.text=list(cex=1.15, font=2), + scales=list(cex=1.15), + main="Density Plot of M1 by Gender", + xlab=list("M1", cex=1.15, font=2), + xlim=c(0,120), # Note the range. + ylab=list("Density", cex=1.15, font=2), + aspect=0.25, + layout = c(1,2), # Note: 1 Column by 2 Rows. + col="red") Waiting to confirm page change... > > par(ask=TRUE) # 1 Column by 2 Rows Density Plot > lattice::densityplot(~ GenRegM1M2.df$M1 | + GenRegM1M2.df$Region, + type="count", # Note: count + par.settings=simpleTheme(lwd=2), + par.strip.text=list(cex=1.15, font=2), + scales=list(cex=1.15), + main="Density Plot of M1 by Region", + xlab=list("M1", cex=1.15, font=2), + xlim=c(0,120), # Note the range. + ylab=list("Density", cex=1.15, font=2), + aspect=0.25, + layout = c(1,2), # Note: 1 Column by 2 Rows. + col="red") Waiting to confirm page change... > > par(ask=TRUE) # 1 Column by 1 Row Density Plot > lattice::densityplot(~ GenRegM1M2.df$M2, + type="count", # Note: count + par.settings=simpleTheme(lwd=2), + par.strip.text=list(cex=1.15, font=2), + scales=list(cex=1.15), + main="Density Plot of M2", + xlab=list("M2", cex=1.15, font=2), + xlim=c(0,2.25), # Note the range. + ylab=list("Density", cex=1.15, font=2), + aspect=1, + layout = c(1,1), # Note: 1 Column by 1 Row. + col="red") Waiting to confirm page change... > > par(ask=TRUE) # 1 Column by 2 Rows Density Plot > lattice::densityplot(~ GenRegM1M2.df$M2 | + GenRegM1M2.df$Gender.recode, + type="count", # Note: count + par.settings=simpleTheme(lwd=2), + par.strip.text=list(cex=1.15, font=2), + scales=list(cex=1.15), + main="Density Plot of M2 by Gender", + xlab=list("M2", cex=1.15, font=2), + xlim=c(0,2.25), # Note the range. + ylab=list("Density", cex=1.15, font=2), + aspect=0.25, + layout = c(1,2), # Note: 1 Column by 2 Rows. + col="red") Waiting to confirm page change... > > par(ask=TRUE) # 1 Column by 2 Rows Density Plot > lattice::densityplot(~ GenRegM1M2.df$M2 | + GenRegM1M2.df$Region, + type="count", # Note: count + par.settings=simpleTheme(lwd=2), + par.strip.text=list(cex=1.15, font=2), + scales=list(cex=1.15), + main="Density Plot of M2 by Region", + xlab=list("M2", cex=1.15, font=2), + xlim=c(0,2.25), # Note the range. + ylab=list("Density", cex=1.15, font=2), + aspect=0.25, + layout = c(1,2), # Note: 1 Column by 2 Rows. + col="red") Waiting to confirm page change... > > ---------- Thomas W. MacFarland, Ed.D. Senior Research Associate; Institutional Effectiveness and Associate Professor Nova Southeastern University Voice 954-262-5395 [hidden email] -----Original Message----- From: SPSSX(r) Discussion [mailto:[hidden email]] On Behalf Of markecb Sent: Wednesday, July 24, 2013 5:08 AM To: [hidden email] Subject: 2 histogram side by side How to make something like this. I know how to make separate histograms but how to make it together? <http://spssx-discussion.1045642.n5.nabble.com/file/n5721321/spsshistogramexample.jpg> -- View this message in context: http://spssx-discussion.1045642.n5.nabble.com/2-histogram-side-by-side-tp5721321.html Sent from the SPSSX Discussion mailing list archive at Nabble.com. ===================== To manage your subscription to SPSSX-L, send a message to [hidden email] (not to SPSSX-L), with no body text except the command. To leave the list, send the command SIGNOFF SPSSX-L For a list of commands to manage subscriptions, send the command INFO REFCARD ===================== To manage your subscription to SPSSX-L, send a message to [hidden email] (not to SPSSX-L), with no body text except the command. To leave the list, send the command SIGNOFF SPSSX-L For a list of commands to manage subscriptions, send the command INFO REFCARD |
|
|
In reply to this post by markecb
It seems to me that this is a highly questionable
chart. What does the X axis actually represent? It seems to
be a composite of values of the variable and a categorical variable. For
example, the interval between 20 and 30 has two bars of different colors.
Is the blue bar really supposed to correspond to the values between
20 and 25 and the red bar values between 25 and (almost) 30? And
there are gaps that do not belong in a histogram.
You might consider a population pyramid or a paneled chart instead if you want to compare two distributions. That can easily be done from the chart builder. I should note also that ggplot2 is an implementation in R of the grammar of graphics technology that was developed at SPSS. Jon Peck (no "h") aka Kim Senior Software Engineer, IBM [hidden email] phone: 720-342-5621 From: markecb <[hidden email]> To: [hidden email], Date: 07/24/2013 03:08 AM Subject: [SPSSX-L] 2 histogram side by side Sent by: "SPSSX(r) Discussion" <[hidden email]> How to make something like this. I know how to make separate histograms but how to make it together? <http://spssx-discussion.1045642.n5.nabble.com/file/n5721321/spsshistogramexample.jpg> -- View this message in context: http://spssx-discussion.1045642.n5.nabble.com/2-histogram-side-by-side-tp5721321.html Sent from the SPSSX Discussion mailing list archive at Nabble.com. ===================== To manage your subscription to SPSSX-L, send a message to [hidden email] (not to SPSSX-L), with no body text except the command. To leave the list, send the command SIGNOFF SPSSX-L For a list of commands to manage subscriptions, send the command INFO REFCARD |
|
|
In reply to this post by markecb
If your data are as separate variables in the file you can use multiple element statements to superimpose them on the same graph. Also, you could reshape the data into long format so both variables are in the same column and then map those categories to different aesthetics. Examples below.
Unfortunately, it doesn't appear dodging works for histograms (you need a categorical x-axis to use dodging), so you can't recreate that exact chart (which I wouldn't exactly call a histogram as presented, see the ggplot2 docs for an example of a dodged histogram). In the first example I use transparency so that you can see each histogram even when X2 covers X1 completely. 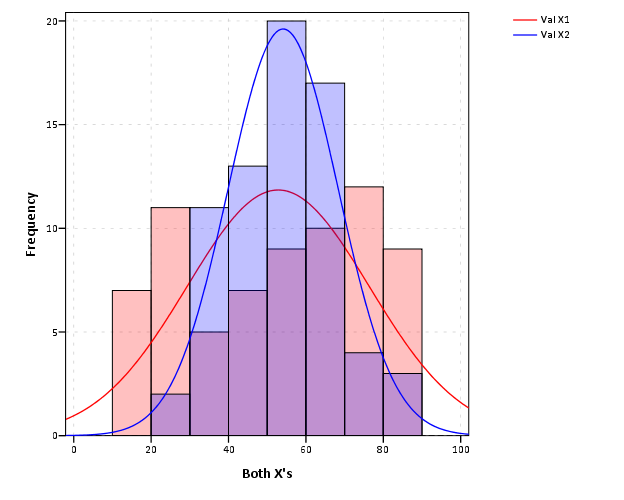 I really dislike clustered bar charts, and so some alternative suggestions for better presentation; - use small multiple histograms, with each histogram in separate panels - or visualize the difference in the frequency between each histogram directly - instead of using bars to plot the histograms use lines (stepped if you prefer), so the estimates don't occlude each other so much - just plot a line for the kernel density estimate of each distribution - use side by side box plots I may need to do a blog-post sometime on how to make hanging rootograms. What comparisons you want to make should guide what plot to use, e.g. differences between distributions you might better plot the actual difference, just visually assessing the scale and location of each separately you might want to use small multiples etc. *********************************************. input program. loop #i = 1 to 70. compute x1 = RV.UNIFORM(10,90). compute x2 = RV.NORMAL(50,15). end case. end loop. end file. end input program. dataset name histo. format x1 x2 (F2.0). *Superimposing histograms. GGRAPH /GRAPHDATASET NAME="graphdataset" VARIABLES=x1 x2 /GRAPHSPEC SOURCE=INLINE. BEGIN GPL SOURCE: s=userSource(id("graphdataset")) DATA: x1=col(source(s), name("x1")) DATA: x2=col(source(s), name("x2")) GUIDE: axis(dim(1), label("Both X's")) GUIDE: axis(dim(2), label("Frequency")) SCALE: cat(aesthetic(aesthetic.color), map(("Val X1", color.red), ("Val X2", color.blue))) ELEMENT: interval(position(summary.count(bin.rect(x1, binStart(0), binWidth(10)))), color.interior("Val X1"), transparency.interior(transparency."0.75")) ELEMENT: line(position(density.normal(x1)), color.interior("Val X1")) ELEMENT: interval(position(summary.count(bin.rect(x2, binStart(0), binWidth(10)))), color.interior("Val X2"), transparency.interior(transparency."0.75")) ELEMENT: line(position(density.normal(x2)), color.interior("Val X2")) END GPL. *Check out the other density functions, like kernel as well. *You can reshape, and either stack or dodge them. varstocases /make x from x1 x2 /index id. value labels id 1 'X1' 2 'X2'. *Bin the values and dodge. compute XBinned = TRUNC(x/10)*10. formats XBinned (F2.0). GGRAPH /GRAPHDATASET NAME="graphdataset" VARIABLES=XBinned[LEVEL=ORDINAL] COUNT()[name="COUNT"] id MISSING=LISTWISE REPORTMISSING=NO /GRAPHSPEC SOURCE=INLINE. BEGIN GPL SOURCE: s=userSource(id("graphdataset")) DATA: XBinned=col(source(s), name("XBinned"), unit.category()) DATA: COUNT=col(source(s), name("COUNT")) DATA: id=col(source(s), name("id"), unit.category()) COORD: rect(dim(1,2), cluster(3,0)) GUIDE: axis(dim(3), label("XBinned")) GUIDE: axis(dim(2), label("Count")) GUIDE: legend(aesthetic(aesthetic.color.interior)) SCALE: cat(dim(3)) SCALE: linear(dim(2), include(0)) SCALE: cat(aesthetic(aesthetic.color), map(("1", color.red), ("2", color.blue))) SCALE: cat(dim(1), include("1", "2")) ELEMENT: interval(position(id*COUNT*XBinned), color.interior(id),shape.interior(shape.square)) END GPL. *Superimposing a normal curve is difficult, as to dodge you need a categorical variable for the x axis. *You can also do things like a population pyramid or a small multiples with histograms in each panel. *********************************************. |
|
|
In a similar vein, the STATS SUBGROUP PLOTS
extension command (available from the SPSS Community site at www.ibm.com/developerworks/spssdevcentral
and requires the Python Essentials) can produce sets of overlaid plots
as area charts, bars, or a kernel smooth. It uses transparency and
color differences to make the subgroup and overall distributions visible
when overlaid. The command works by generating and running the necessary
GPL code.
Newer versions of Statistics include this extension command in the Python Essentials. Jon Peck (no "h") aka Kim Senior Software Engineer, IBM [hidden email] phone: 720-342-5621 From: Andy W <[hidden email]> To: [hidden email], Date: 07/24/2013 06:48 AM Subject: Re: [SPSSX-L] 2 histogram side by side Sent by: "SPSSX(r) Discussion" <[hidden email]> If your data are as separate variables in the file you can use multiple element statements to superimpose them on the same graph. Also, you could reshape the data into long format so both variables are in the same column and then map those categories to different aesthetics. Examples below. Unfortunately, it doesn't appear dodging works for histograms (you need a categorical x-axis to use dodging), so you can't recreate that exact chart (which I wouldn't exactly call a histogram as presented, see the ggplot2 docs <http://docs.ggplot2.org/current/geom_histogram.html> for an example of a dodged histogram). In the first example I use transparency so that you can see each histogram even when X2 covers X1 completely. <http://spssx-discussion.1045642.n5.nabble.com/file/n5721326/SUPERHISTO0.png> I really dislike clustered bar charts, and so some alternative suggestions for better presentation; - use small multiple histograms, with each histogram in separate panels - or visualize the difference in the frequency between each histogram directly - instead of using bars to plot the histograms use lines (stepped if you prefer), so the estimates don't occlude each other so much - just plot a line for the kernel density estimate of each distribution - use side by side box plots I may need to do a blog-post sometime on how to make hanging rootograms. What comparisons you want to make should guide what plot to use, e.g. differences between distributions you might better plot the actual difference, just visually assessing the scale and location of each separately you might want to use small multiples etc. *********************************************. input program. loop #i = 1 to 70. compute x1 = RV.UNIFORM(10,90). compute x2 = RV.NORMAL(50,15). end case. end loop. end file. end input program. dataset name histo. format x1 x2 (F2.0). *Superimposing histograms. GGRAPH /GRAPHDATASET NAME="graphdataset" VARIABLES=x1 x2 /GRAPHSPEC SOURCE=INLINE. BEGIN GPL SOURCE: s=userSource(id("graphdataset")) DATA: x1=col(source(s), name("x1")) DATA: x2=col(source(s), name("x2")) GUIDE: axis(dim(1), label("Both X's")) GUIDE: axis(dim(2), label("Frequency")) SCALE: cat(aesthetic(aesthetic.color), map(("Val X1", color.red), ("Val X2", color.blue))) ELEMENT: interval(position(summary.count(bin.rect(x1, binStart(0), binWidth(10)))), color.interior("Val X1"), transparency.interior(transparency."0.75")) ELEMENT: line(position(density.normal(x1)), color.interior("Val X1")) ELEMENT: interval(position(summary.count(bin.rect(x2, binStart(0), binWidth(10)))), color.interior("Val X2"), transparency.interior(transparency."0.75")) ELEMENT: line(position(density.normal(x2)), color.interior("Val X2")) END GPL. *Check out the other density functions, like kernel as well. *You can reshape, and either stack or dodge them. varstocases /make x from x1 x2 /index id. value labels id 1 'X1' 2 'X2'. *Bin the values and dodge. compute XBinned = TRUNC(x/10)*10. formats XBinned (F2.0). GGRAPH /GRAPHDATASET NAME="graphdataset" VARIABLES=XBinned[LEVEL=ORDINAL] COUNT()[name="COUNT"] id MISSING=LISTWISE REPORTMISSING=NO /GRAPHSPEC SOURCE=INLINE. BEGIN GPL SOURCE: s=userSource(id("graphdataset")) DATA: XBinned=col(source(s), name("XBinned"), unit.category()) DATA: COUNT=col(source(s), name("COUNT")) DATA: id=col(source(s), name("id"), unit.category()) COORD: rect(dim(1,2), cluster(3,0)) GUIDE: axis(dim(3), label("XBinned")) GUIDE: axis(dim(2), label("Count")) GUIDE: legend(aesthetic(aesthetic.color.interior)) SCALE: cat(dim(3)) SCALE: linear(dim(2), include(0)) SCALE: cat(aesthetic(aesthetic.color), map(("1", color.red), ("2", color.blue))) SCALE: cat(dim(1), include("1", "2")) ELEMENT: interval(position(id*COUNT*XBinned), color.interior(id),shape.interior(shape.square)) END GPL. *Superimposing a normal curve is difficult, as to dodge you need a categorical variable for the x axis. *You can also do things like a population pyramid or a small multiples with histograms in each panel. *********************************************. ----- Andy W [hidden email] http://andrewpwheeler.wordpress.com/ -- View this message in context: http://spssx-discussion.1045642.n5.nabble.com/2-histogram-side-by-side-tp5721321p5721326.html Sent from the SPSSX Discussion mailing list archive at Nabble.com. ===================== To manage your subscription to SPSSX-L, send a message to [hidden email] (not to SPSSX-L), with no body text except the command. To leave the list, send the command SIGNOFF SPSSX-L For a list of commands to manage subscriptions, send the command INFO REFCARD |
|
Administrator
|
In reply to this post by markecb
I don't think anyone has suggested using overlapping frequency polygons--and I believe it is fairly standard to use them to display two or more overlapping frequency distributions. I don't know GGRAPH well enough to know if it can produce frequency polygons easily. But here's a rough and ready approach that might give something good enough for your purposes. (It's not perfect, because it doesn't drop lines to 0 on the Y-axis at each end, for example, as would be done for a true frequency polygon.)
* Change the path below to indicate where the SPSS * sample data files are stored on your PC. FILE HANDLE TheDataFile /NAME="C:\SPSSdata\survey_sample.sav". NEW FILE. DATASET CLOSE all. GET FILE = "TheDataFile". GRAPH /LINE(MULTIPLE)=COUNT BY age BY sex. * If something a bit smoother is desired, * make the X-axis variable a bit coarser. * In this case, make Age Groups, for example. DESCRIPTIVES age. COMPUTE AgeGroup = TRUNC(Age/10). FORMATS AgeGroup(f2.0). MEANS age by AgeGroup / cells = count min max. VARIABLE LABELS AgeGroup "Age". VALUE LABELS AgeGroup 1 "10-19" 2 "20-29" 3 "30-39" 4 "40-49" 5 "50-59" 6 "60-69" 7 "70-79" 8 "80-89" . GRAPH /LINE(MULTIPLE)=COUNT BY AgeGroup BY sex. HTH.
--
Bruce Weaver bweaver@lakeheadu.ca http://sites.google.com/a/lakeheadu.ca/bweaver/ "When all else fails, RTFM." PLEASE NOTE THE FOLLOWING: 1. My Hotmail account is not monitored regularly. To send me an e-mail, please use the address shown above. 2. The SPSSX Discussion forum on Nabble is no longer linked to the SPSSX-L listserv administered by UGA (https://listserv.uga.edu/). |

|
|
That was in the note I sent earlier about
STATSSUBGROUP PLOTS. Population pyramids would be another reasonable
choice.
Jon Peck (no "h") aka Kim Senior Software Engineer, IBM [hidden email] phone: 720-342-5621 From: Bruce Weaver <[hidden email]> To: [hidden email], Date: 07/25/2013 02:37 PM Subject: Re: [SPSSX-L] 2 histogram side by side Sent by: "SPSSX(r) Discussion" <[hidden email]> I don't think anyone has suggested using overlapping frequency polygons--and I believe it is fairly standard to use them to display two or more overlapping frequency distributions. I don't know GGRAPH well enough to know if it can produce frequency polygons easily. But here's a rough and ready approach that might give something good enough for your purposes. (It's not perfect, because it doesn't drop lines to 0 on the Y-axis at each end, for example, as would be done for a true frequency polygon.) * Change the path below to indicate where the SPSS * sample data files are stored on your PC. FILE HANDLE TheDataFile /NAME="C:\SPSSdata\survey_sample.sav". NEW FILE. DATASET CLOSE all. GET FILE = "TheDataFile". GRAPH /LINE(MULTIPLE)=COUNT BY age BY sex. * If something a bit smoother is desired, * make the X-axis variable a bit coarser. * In this case, make Age Groups, for example. DESCRIPTIVES age. COMPUTE AgeGroup = TRUNC(Age/10). FORMATS AgeGroup(f2.0). MEANS age by AgeGroup / cells = count min max. VARIABLE LABELS AgeGroup "Age". VALUE LABELS AgeGroup 1 "10-19" 2 "20-29" 3 "30-39" 4 "40-49" 5 "50-59" 6 "60-69" 7 "70-79" 8 "80-89" . GRAPH /LINE(MULTIPLE)=COUNT BY AgeGroup BY sex. HTH. markecb wrote > How to make something like this. > I know how to make separate histograms but how to make it together? <http://spssx-discussion.1045642.n5.nabble.com/file/n5721321/spsshistogramexample.jpg> ----- -- Bruce Weaver [hidden email] http://sites.google.com/a/lakeheadu.ca/bweaver/ "When all else fails, RTFM." NOTE: My Hotmail account is not monitored regularly. To send me an e-mail, please use the address shown above. -- View this message in context: http://spssx-discussion.1045642.n5.nabble.com/2-histogram-side-by-side-tp5721321p5721369.html Sent from the SPSSX Discussion mailing list archive at Nabble.com. ===================== To manage your subscription to SPSSX-L, send a message to [hidden email] (not to SPSSX-L), with no body text except the command. To leave the list, send the command SIGNOFF SPSSX-L For a list of commands to manage subscriptions, send the command INFO REFCARD |
|
|
It’s very easy to provide overlapping frequency polygons as bars or areas without the offset using GPL. When I make them, I specify semi-transparent fills so that the topmost element doesn’t obscure the lower element when its value is less. This is probably what Kim’s GPL does. From: SPSSX(r) Discussion [mailto:[hidden email]] On Behalf Of Jon K Peck That was in the note I sent earlier about STATSSUBGROUP PLOTS. Population pyramids would be another reasonable choice.
|
| Free forum by Nabble | Edit this page |