Aggregate multiple variables


|
Happy Friday, Listserv,
I need your help once again. I am trying to get aggregated information using three variables. What I need to know is how many institutions are counted in a stratified cell (we have over 30) by a normed variable. With this the variables I need to include are institution identifier (ACE), weightstrat, and normstat. Clearly I am not doing something right. Is there something else I should try? GET FILE='C:\WEIGHTSTRAT.SAV'. SORT CASES BY ACE WEIGHTSTRAT. AGGREGATE OUTFILE='C:\WEIGHTSTRAT.SAV' /BREAK=ACE WEIGHTSTAT /TOTN=SUM(TOTN) /NORMS=FIRST(NORMSTAT). SAVE OUTFILE=='C:\STRATCOUNT.SAV'. With appreciation, Maria |
|
|
Can you provide an example snippet of data before and what you want the end result to be? I'm having trouble exactly understanding your request. (Given your description yes AGGREGATE seems a likely solution, but I can't tell what is wrong with your current code, or what is the TOTN variable.)
|
Re: Aggregate multiple variables
|
Administrator
|
I don't think the original post has made it to the mailing list yet. Those who are not reading via Nabble can see it here:
http://spssx-discussion.1045642.n5.nabble.com/Aggregate-multiple-variables-td5728170.html
--
Bruce Weaver bweaver@lakeheadu.ca http://sites.google.com/a/lakeheadu.ca/bweaver/ "When all else fails, RTFM." PLEASE NOTE THE FOLLOWING: 1. My Hotmail account is not monitored regularly. To send me an e-mail, please use the address shown above. 2. The SPSSX Discussion forum on Nabble is no longer linked to the SPSSX-L listserv administered by UGA (https://listserv.uga.edu/). |
Re: Aggregate multiple variables
|
|
In reply to this post by Maria Suchard
On Dec 12, 2014; 6:30pm, Maria Suchard wrote (copy-pasted from Nabble):
>I am trying to get aggregated information using three >variables. What I need to know is how many institutions are counted >in a stratified cell (we have over 30) by a normed variable. With >this the variables I need to include are institution identifier >(ACE), weightstrat, and normstat. > >Clearly I am not doing something right. Is there something else I >should try? > >GET FILE='C:\WEIGHTSTRAT.SAV'. > >SORT CASES BY ACE WEIGHTSTRAT. >AGGREGATE OUTFILE='C:\WEIGHTSTRAT.SAV' > /BREAK=ACE WEIGHTSTAT > /TOTN=SUM(TOTN) > /NORMS=FIRST(NORMSTAT). > >SAVE OUTFILE='C:\STRATCOUNT.SAV'. Three small things: + You appear to have one typographical error: in the /BREAK clause, "WEIGHTSTAT" should probably be "WEIGHTSTRAT". + It is very unwise to have your AGGREGATE OUTFILE (C:\WEIGHTSTRAT.SAV) be the same as the file you've just loaded. AGGREGATE summarizes information, and therefore loses a lot of it; you do not want to use it to overwrite the input! The syntax you have will save the *original* data in C:\STRATCOUNT.SAV, and overwrite C:\WEIGHTSTRAT.SAV with the aggregated data; that's probably the reverse of what you wanted. + You don't need the SORT CASES before AGGREGATE. That was once true, but hasn't been for quite a while now.(*) Now, the AGGREGATE as you have it (correcting the typo) will give one record for each institution (ACE value) for each weight stratum (WEIGHTSTRAT value). You say you want "how many institutions are counted in [each] stratified cell", which sounds like you want a single record for each WEIGHTSTRAT value. If you have (possibly) multiple records for each institution for each stratum, you can count institutions within stratum by *two* AGGREGATEs. Like the following -- untested. (Note "OUTFILE=", which replaces the active file with the AGGREGATE output, rather than writing the output to a disk file): GET FILE='C:\WEIGHTSTRAT.SAV'. AGGREGATE OUTFILE=* /BREAK=WEIGHTSTRAT ACE /NRECS 'No. of records for this institution and weight stratum' =NU. AGGREGATE OUTFILE=* /BREAK=WEIGHTSTRAT /NINST 'No. of institutions represented in this weight stratum' /NRECS 'No. of records for this weight stratum' =SUM(NRECS). FORMATS NINST NRECS (F5). That leaves the question, what are TOTN and NORMSTAT, and how do you want those summarized in your final result. ============================================================================ APPENDIX: AGGREGATE and SORT CASES ============================================================================ (*) You need SORT CASES before AGGREGATE if you use the /PRESORTED option to AGGREGATE. However, there's no reason to do that, except in certain very large cases -- at least 100,000 different sets of values for the /BREAK variables. ===================== To manage your subscription to SPSSX-L, send a message to [hidden email] (not to SPSSX-L), with no body text except the command. To leave the list, send the command SIGNOFF SPSSX-L For a list of commands to manage subscriptions, send the command INFO REFCARD |
|
|
In reply to this post by Maria Suchard
Richard,
While not applicable in this instance, I can see the use for presorted in cases beyond case size & breaks. When you using the aggregate functions 'last' or 'first', results may be different than expected when not presorted. For example, if you have a repeating ID with a non-repeating date and you want to capture the last value of a string column ('last' being defined as the latest date of a repeating ID set), if the file is not presorted by ID & date prior to aggregation you wouldn't necessarily get the last date based string value. David, On Sat, Dec 13, 2014 at 1:02 PM, Richard Ristow wrote: > On Dec 12, 2014; 6:30pm, Maria Suchard wrote (copy-pasted from > Nabble): > >> I am trying to get aggregated information using three variables. >> What I need to know is how many institutions are counted in a >> stratified cell (we have over 30) by a normed variable. With this >> the variables I need to include are institution identifier (ACE), >> weightstrat, and normstat. >> >> Clearly I am not doing something right. Is there something else I >> should try? >> >> GET FILE='C:\WEIGHTSTRAT.SAV'. >> >> SORT CASES BY ACE WEIGHTSTRAT. >> AGGREGATE OUTFILE='C:\WEIGHTSTRAT.SAV' >> /BREAK=ACE WEIGHTSTAT >> /TOTN=SUM(TOTN) >> /NORMS=FIRST(NORMSTAT). >> >> SAVE OUTFILE='C:\STRATCOUNT.SAV'. > > Three small things: > + You appear to have one typographical error: in the /BREAK clause, > "WEIGHTSTAT" should probably be "WEIGHTSTRAT". > + It is very unwise to have your AGGREGATE OUTFILE > (C:\WEIGHTSTRAT.SAV) be the same as the file you've just loaded. > AGGREGATE summarizes information, and therefore loses a lot of it; you > do not want to use it to overwrite the input! The syntax you have will > save the *original* data in C:\STRATCOUNT.SAV, and overwrite > C:\WEIGHTSTRAT.SAV with the aggregated data; that's probably the > reverse of what you wanted. > + You don't need the SORT CASES before AGGREGATE. That was once true, > but hasn't been for quite a while now.(*) > > Now, the AGGREGATE as you have it (correcting the typo) will give one > record for each institution (ACE value) for each weight stratum > (WEIGHTSTRAT value). You say you want "how many institutions are > counted in [each] stratified cell", which sounds like you want a > single record for each WEIGHTSTRAT value. > > If you have (possibly) multiple records for each institution for each > stratum, you can count institutions within stratum by *two* > AGGREGATEs. Like the following -- untested. (Note "OUTFILE=", which > replaces the active file with the AGGREGATE output, rather than > writing the output to a disk file): > > GET FILE='C:\WEIGHTSTRAT.SAV'. > > AGGREGATE OUTFILE=* > /BREAK=WEIGHTSTRAT ACE > /NRECS 'No. of records for this institution and weight stratum' > =NU. > > AGGREGATE OUTFILE=* > /BREAK=WEIGHTSTRAT > /NINST 'No. of institutions represented in this weight stratum' > /NRECS 'No. of records for this weight stratum' > =SUM(NRECS). > > FORMATS NINST NRECS (F5). > > That leaves the question, what are TOTN and NORMSTAT, and how do you > want those summarized in your final result. > > > ============================================================================ > APPENDIX: AGGREGATE and SORT CASES > > ============================================================================ > (*) You need SORT CASES before AGGREGATE if you use the /PRESORTED > option to AGGREGATE. However, there's no reason to do that, except in > certain very large cases -- at least 100,000 different sets of values > for the /BREAK variables. ===================== > To manage your subscription to SPSSX-L, send a message to > [hidden email] (not to SPSSX-L), with no body text except > the > command. To leave the list, send the command > SIGNOFF SPSSX-L > For a list of commands to manage subscriptions, send the command > INFO REFCARD ===================== To manage your subscription to SPSSX-L, send a message to [hidden email] (not to SPSSX-L), with no body text except the command. To leave the list, send the command SIGNOFF SPSSX-L For a list of commands to manage subscriptions, send the command INFO REFCARD |
Re: Aggregate multiple variables
|
|
At 05:16 PM 12/13/2014, [hidden email] wrote:
>While not applicable in this instance, I can see the use for >presorted in cases beyond case size & breaks. When you using the >aggregate functions 'last' or 'first', results may be different than >expected when not presorted. Touche; point very well taken. One case where sorting and function FIRST (or LAST) is useful is to find the value of variable A that occurs in conjunction with the largest value of variable B; I've posted solutions like that, myself(*). (*) For example, Date: Wed, 5 Mar 2014 12:13:54 -0500 From: Richard Ristow <[hidden email]> Subject: Re: Select variable name with max value To: [hidden email] ===================== To manage your subscription to SPSSX-L, send a message to [hidden email] (not to SPSSX-L), with no body text except the command. To leave the list, send the command SIGNOFF SPSSX-L For a list of commands to manage subscriptions, send the command INFO REFCARD |
|
Administrator
|
In reply to this post by Richard Ristow
"+ It is very unwise to have your AGGREGATE OUTFILE
(C:\WEIGHTSTRAT.SAV) be the same as the file you've just loaded. " In fact it is impossible. DATA LIST FREE / a b. BEGIN DATA 1 1 1 2 1 1 2 2 2 1 1 2 1 3 3 4 3 5 3 6 END DATA. SAVE OUTFILE "C:\TEMP\test.sav". AGGREGATE OUTFILE "C:\TEMP\test.sav" / BREAK a / Sb=SUM(b). /* >Error # 62 in column 20. Text: C:\TEMP\test.sav /*>The file is already in use. /*>Execution of this command stops. OTOH: I would call into question code which attempts to do so. I suggest that OP look into DATASET DECLARE/ACTIVATE command(s).
Please reply to the list and not to my personal email.
Those desiring my consulting or training services please feel free to email me. --- "Nolite dare sanctum canibus neque mittatis margaritas vestras ante porcos ne forte conculcent eas pedibus suis." Cum es damnatorum possederunt porcos iens ut salire off sanguinum cliff in abyssum?" |
Re: Aggregate multiple variables
|
|
In reply to this post by Andy W
Good morning,
Thank you for your responses. I have over 340 institutions- each are defined by a weightstrat, and a normed grouping =normstat (1,0), so I have 3 variables to take into consideration, ACE (instituion identifier), weightstrat, and normstat. I have attached is a sample copy of the output I am trying to recreate. The first variable is just renamed normstat, we should have a min 5 counts if first=1. Obviously, I didn't create the attached output, and there is no code to go with it either. Any help is appreciated. thank you, Maria 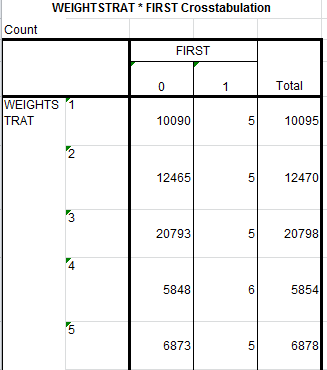 |
|
Administrator
|
Richard Ristow Dec 13, 2014; 2:02pm
Provided you with explicit code to address your initial query beginning this thread. Please review! If nothing else post the code you have tried and explain how it fails to answer your question!
Please reply to the list and not to my personal email.
Those desiring my consulting or training services please feel free to email me. --- "Nolite dare sanctum canibus neque mittatis margaritas vestras ante porcos ne forte conculcent eas pedibus suis." Cum es damnatorum possederunt porcos iens ut salire off sanguinum cliff in abyssum?" |
Re: Aggregate multiple variables
|
|
Hi David,
Thank you for your post. I have tried the code you suggested, modified a little bit and it worked. Thank you. Maria |
«
Return to SPSSX Discussion
|
1 view|%1 views
| Free forum by Nabble | Edit this page |