Vik,
Please do not take this the wrong way, but I'm EXTREMELY busy and
therefore cannot respond to your question in a comprehensive way.
Moreover, your question goes beyond your original question, and speaks
to a basic question about "dummy coding" (a.k.a. indicator coding) in
regression. This topic is covered in virtually any regression textbook
that I've ever seen. I'm sure it has come up a few times on SPSS-L as
well.
The concept doesn't change if you have two levels of an independent
categorical variable (e.g., gender) or multiple levels (e.g., race),
nor does it change if you're dealing with linear regression or
(binary, ordinal, etc.) logistic regression. The bottom line is that
you or the procedure if it allows for the specification of categorical
independent variables converts the single categorical independent
variable into k MINUS 1 binary (coded 0/1) "dummy variables," where k
is the number of levels of your independent categorical variable. The
k - 1 dummy variables capture all the information from the single
categorical variable. You will obtain regression coefficients
associated with each non-redundant dummy variable, and of course,
these regression coefficients along with their respective
non-redundant dummy variables need to be incorporated into the linear
predictor(s) (e.g., eta1, eta2, etc.).
Maybe somebody else is willing to jump in at this point to help you out.
Best,
Ryan
On Thu, Nov 1, 2012 at 2:40 AM, Vik Rubenfeld <
[hidden email]> wrote:
> This is fantastic. I have almost got it.
>
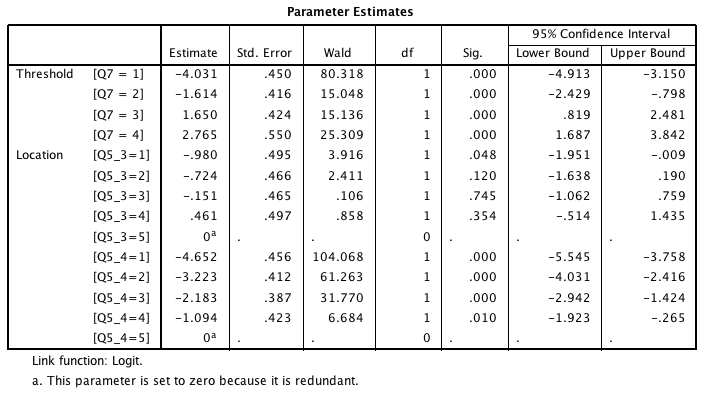
> In the ucla data set, the variables pared and public have just two levels,
> and so they get only one parameter estimate each. Some of the variables in
> my data set have 5 levels, and so get 4 parameter estimates each, one for
> each level minus the highest level. Here are the parameter estimates for a
> test run using two predictor variables:
>
> PLUM Q7 BY Q5_3 Q5_4
> /LINK=LOGIT
> /PRINT=PARAMETER SUMMARY
> /SAVE=ESTPROB.
>
> <
http://spssx-discussion.1045642.n5.nabble.com/file/n5715993/Screen_shot_2012-10-31_at_11.26.19_PM.png>
>
> What is the correct way to apply this line of the algorithm:
>
> compute #eta0_subj1 = 2.203323 - (1.047664*0 + (-0.058683)*0 +
> 0.615746*3.260000).
>
> ...for predictor variables that have more than one parameter estimate? In
> other words, which of the four possible parameter estimates is to be used?
> I would have thought it would be the one that matches the observed value of
> the predictor variable for each case - but if the observed value is the
> highest possible value, then there is no matching parameter estimate. What
> am I missing?
>
> I am attaching the test data set used in this example.
>
> test-data.sav
> <
http://spssx-discussion.1045642.n5.nabble.com/file/n5715993/test-data.sav>
>
>
>
> --
> View this message in context:
http://spssx-discussion.1045642.n5.nabble.com/Deriving-Formula-from-Ordinal-Regression-Results-to-Classify-New-Cases-tp5715848p5715993.html> Sent from the SPSSX Discussion mailing list archive at Nabble.com.
>
> =====================
> To manage your subscription to SPSSX-L, send a message to
>
[hidden email] (not to SPSSX-L), with no body text except the
> command. To leave the list, send the command
> SIGNOFF SPSSX-L
> For a list of commands to manage subscriptions, send the command
> INFO REFCARD
=====================
To manage your subscription to SPSSX-L, send a message to
[hidden email] (not to SPSSX-L), with no body text except the
command. To leave the list, send the command
SIGNOFF SPSSX-L
For a list of commands to manage subscriptions, send the command
INFO REFCARD