How to populate blank row header labels

How to populate blank row header labels

|
Hi, The default output for a pivot table with nested variables shows each value label just once, particularly for the ‘higher-level’ variables e.g.
I’m interested to know whether it’s possible, either in syntax or otherwise, to automatically populate every relevant row with the labels from the higher-level variables e.g.:-
Any ideas or suggestions towards this would be gratefully accepted! Thanks, Mark Mark Lenel T: +44 (0)1483 510310 || F: +44 (0)1483 510319 || E: [hidden email] ||
W: www.arkenford.co.uk |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Re: How to populate blank row header labels
|
|
Pivot table labels are actually hierarchical,
so you can't populate them the way you want. The only solution I
can think of is to create a combined variable and assign it value labels
that represent the combinations.
Jon Peck (no "h") aka Kim Senior Software Engineer, IBM [hidden email] new phone: 720-342-5621 From: Mark Lenel <[hidden email]> To: [hidden email], Date: 10/29/2012 04:47 AM Subject: [SPSSX-L] How to populate blank row header labels Sent by: "SPSSX(r) Discussion" <[hidden email]> Hi, The default output for a pivot table with nested variables shows each value label just once, particularly for the ‘higher-level’ variables e.g.
I’m interested to know whether it’s possible, either in syntax or otherwise, to automatically populate every relevant row with the labels from the higher-level variables e.g.:-
Any ideas or suggestions towards this would be gratefully accepted! Thanks, Mark Mark Lenel Director Arkenford Ltd T: +44 (0)1483 510310 || F: +44 (0)1483 510319 || E: Mark.Lenel@... || W: www.arkenford.co.uk |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Re: How to populate blank row header labels
|
|
In reply to this post by Mark Lenel
The easiest way to do it is to copy the table into Excel, add labels and format it the way you want.
Henry Ilian _ From: SPSSX(r) Discussion [[hidden email]] On Behalf Of Mark Lenel [[hidden email]] Sent: Monday, October 29, 2012 6:43 AM To: [hidden email] Subject: How to populate blank row header labels Hi, The default output for a pivot table with nested variables shows each value label just once, particularly for the ‘higher-level’ variables e.g. Count Male UK 4090 France 3736 Germany 3936 Italy 4039 Spain 3365 US 0 Female UK 4313 France 4138 Germany 4388 Italy 4151 Spain 3363 US 0 I’m interested to know whether it’s possible, either in syntax or otherwise, to automatically populate every relevant row with the labels from the higher-level variables e.g.:- Count Male UK 4090 Male France 3736 Male Germany 3936 Male Italy 4039 Male Spain 3365 Female UK 4313 Female France 4138 Female Germany 4388 Female Italy 4151 Female Spain 3363 Any ideas or suggestions towards this would be gratefully accepted! Thanks, Mark Mark Lenel Director Arkenford Ltd T: +44 (0)1483 510310 || F: +44 (0)1483 510319 || E: [hidden email]<mailto:[hidden email]> || W: www.arkenford.co.uk<http://www.arkenford.co.uk/> Confidentiality Notice: This e-mail communication, and any attachments, contains confidential and privileged information for the exclusive use of the recipient(s) named above. If you are not an intended recipient, or the employee or agent responsible to deliver it to an intended recipient, you are hereby notified that you have received this communication in error and that any review, disclosure, dissemination, distribution or copying of it or its contents is prohibited. If you have received this communication in error, please notify me immediately by replying to this message and delete this communication from your computer. Thank you. ===================== To manage your subscription to SPSSX-L, send a message to [hidden email] (not to SPSSX-L), with no body text except the command. To leave the list, send the command SIGNOFF SPSSX-L For a list of commands to manage subscriptions, send the command INFO REFCARD |
Re: How to populate blank row header labels
|
|
In reply to this post by Mark Lenel
Why do you want to do this? From: SPSSX(r) Discussion [mailto:[hidden email]] On Behalf Of Mark Lenel Hi, The default output for a pivot table with nested variables shows each value label just once, particularly for the ‘higher-level’ variables e.g.
I’m interested to know whether it’s possible, either in syntax or otherwise, to automatically populate every relevant row with the labels from the higher-level variables e.g.:-
Any ideas or suggestions towards this would be gratefully accepted! Thanks, Mark Mark Lenel T: +44 (0)1483 510310 || F: +44 (0)1483 510319 || E: [hidden email] || W: www.arkenford.co.uk |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Automatic reply: How to populate blank row header labels
|
|
In reply to this post by henryilian
Hello,
Due to Hurricane Sandy, Temple University is closed on Monday, October 29 and Tuesday, October 30. I will check email when I can, and respond where necessary.
If you are an applicant to a Temple graduate program and have a question about the status of your application, please be patient, we will respond to you once the University opens after the storm.
If you are an undergraduate applicant, someone from Undergraduate Admissions will respond to you soon.
If you are having an issue with the online application system, please contact our Help Desk ([hidden email]).
Best,
Michael Toner
|
Re: How to populate blank row header labels
|
|
In reply to this post by Mark Lenel
If you just want to write out the lines -
You can aggregate on Sex and Country to get the Counts; and then you can write a simple Report that shows the var labels instead of the values. -- Rich Ulrich Date: Mon, 29 Oct 2012 10:43:36 +0000 From: [hidden email] Subject: How to populate blank row header labels To: [hidden email] Hi,
The default output for a pivot table with nested variables shows each value label just once, particularly for the ‘higher-level’ variables e.g.
I’m interested to know whether it’s possible, either in syntax or otherwise, to automatically populate every relevant row with the labels from the higher-level variables e.g.:-
Any ideas or suggestions towards this would be gratefully accepted!
Thanks, Mark
Mark Lenel T: +44 (0)1483 510310 || F: +44 (0)1483 510319 || E: [hidden email] || W: www.arkenford.co.uk
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Re: How to populate blank row header labels
|
|
In reply to this post by Jon K Peck
A hack I use is to nest the original nesting variables twice:
ie: get file="C:\Program Files\IBM\SPSS\Statistics\22\Samples\English\Employee data.sav". set tvars=labels tnumbers=labels. ctables /vlabels variables=gender educ display=none /table (gender>educ)[c] /categories variables=all empty=exclude. ctables /vlabels variables=gender educ display=none /table (gender>educ>gender>educ)[c] /categories variables=all empty=exclude. 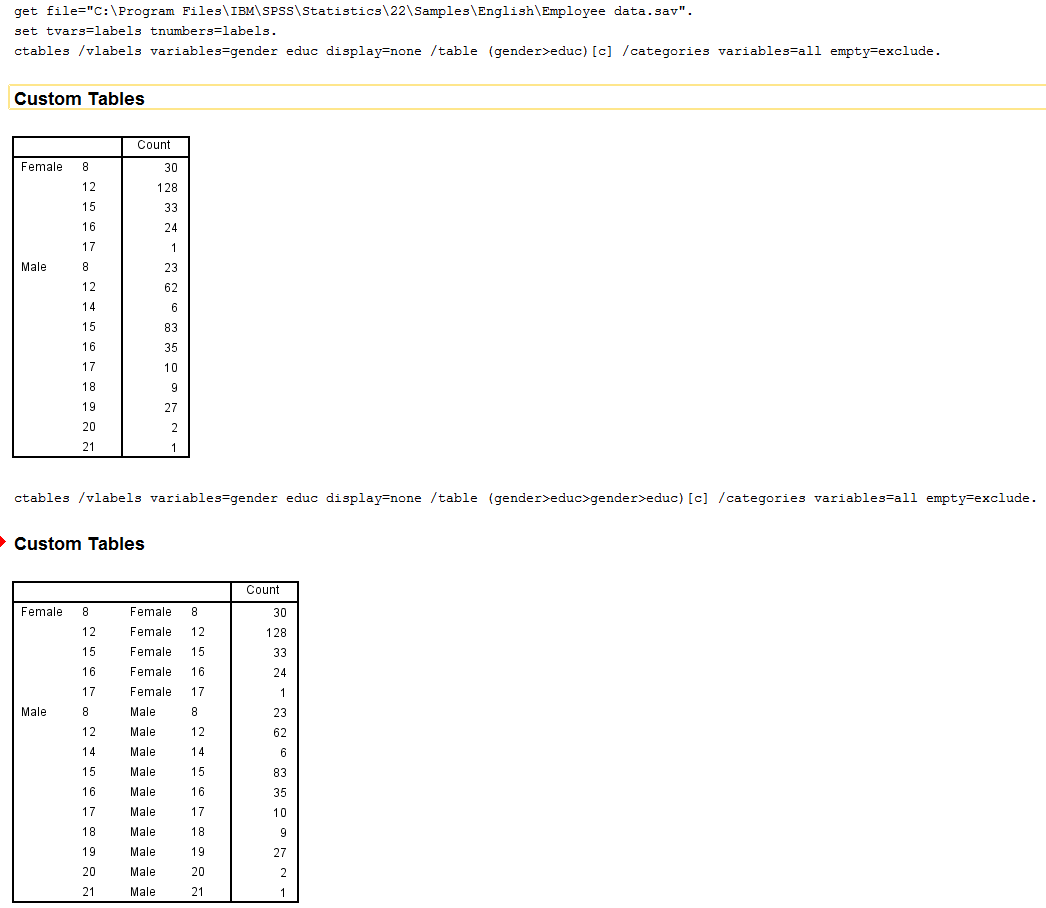 This then produces the repeated labels but all that is left to do then is delete the additional/redundant columns. Note this will work only for counts, if then attempting to extract column %, it will give 100% in each row... Jon, I tried deleting those redundant columns to the left using below but I don't know how to reference the label columns, it only reference starting from the data columns: SPSSINC MODIFY TABLES subtype="customtable" SELECT=-1 DIMENSION= columns LEVEL = -1 PROCESS = PRECEDING HIDE=TRUE /STYLES APPLYTO=BOTH. Also, could SPSSINC MODIFY TABLES be used to fill in those blank labels for nested cells instead of this double nesting approach? |
Re: How to populate blank row header labels
|
|
How about this:
SPSSINC MODIFY TABLES subtype="customtable" DIMENSION= COLUMNS PROCESS = PRECEDING /WIDTHS ROWLABELS = 0 1 2 ROWLABELWIDTHS=0 0 0 /STYLES APPLYTO=LABELS. Jon Peck (no "h") aka Kim Senior Software Engineer, IBM [hidden email] phone: 720-342-5621 From: Jignesh Sutar <[hidden email]> To: [hidden email] Date: 01/07/2015 11:11 AM Subject: Re: [SPSSX-L] How to populate blank row header labels Sent by: "SPSSX(r) Discussion" <[hidden email]> A hack I use is to nest the original nesting variables twice: ie: get file="C:\Program Files\IBM\SPSS\Statistics\22\Samples\English\Employee data.sav". set tvars=labels tnumbers=labels. ctables /vlabels variables=gender educ display=none /table (gender>educ)[c] /categories variables=all empty=exclude. ctables /vlabels variables=gender educ display=none /table (gender>educ>gender>educ)[c] /categories variables=all empty=exclude. <http://spssx-discussion.1045642.n5.nabble.com/file/n5728366/Capture.png> This then produces the repeated labels but all that is left to do then is delete the additional/redundant columns. Note this will work only for counts, if then attempting to extract column %, it will give 100% in each row... *Jon*, I tried deleting those redundant columns to the left using below but I don't know how to reference the label columns, it only reference starting from the data columns: SPSSINC MODIFY TABLES subtype="customtable" SELECT=-1 DIMENSION= columns LEVEL = -1 PROCESS = PRECEDING HIDE=TRUE /STYLES APPLYTO=BOTH. Also, could SPSSINC MODIFY TABLES be used to fill in those blank labels for nested cells instead of this double nesting approach? -- View this message in context: http://spssx-discussion.1045642.n5.nabble.com/How-to-populate-blank-row-header-labels-tp5715908p5728366.html Sent from the SPSSX Discussion mailing list archive at Nabble.com. ===================== To manage your subscription to SPSSX-L, send a message to [hidden email] (not to SPSSX-L), with no body text except the command. To leave the list, send the command SIGNOFF SPSSX-L For a list of commands to manage subscriptions, send the command INFO REFCARD ===================== To manage your subscription to SPSSX-L, send a message to [hidden email] (not to SPSSX-L), with no body text except the command. To leave the list, send the command SIGNOFF SPSSX-L For a list of commands to manage subscriptions, send the command INFO REFCARD |
Re: How to populate blank row header labels
|
|
Thanks Jon, That works a treat but how exactly does that work..? Why are there reference to 3 ROWLABELS? Trying to understand how that function requires its arguments as it can be very useful but also is quite complicated... On 7 January 2015 at 18:30, Jon K Peck <[hidden email]> wrote: How about this: |
Re: How to populate blank row header labels
|
|
There are actually three row labels in
that table, but the first one is already hidden, so there are three numbers.
If you open the table in the pt editor and view the pivot trays,
you see the Row and Column labels. CTABLES output are structured
with invisible dimensions in order to prevent pivoting, because they can
contain nested levels that would not pivot properly.
You could just ignore the zeroth label column and write the command as SPSSINC MODIFY TABLES subtype="customtable" DIMENSION= COLUMNS PROCESS = PRECEDING /WIDTHS ROWLABELS = 1 2 ROWLABELWIDTHS= 0 0 /STYLES APPLYTO=LABELS. Setting the label width to zero hides it. Jon Peck (no "h") aka Kim Senior Software Engineer, IBM [hidden email] phone: 720-342-5621 From: Jignesh Sutar <[hidden email]> To: Jon K Peck/Chicago/IBM@IBMUS Cc: "[hidden email]" <[hidden email]> Date: 01/07/2015 11:41 AM Subject: Re: How to populate blank row header labels Sent by: [hidden email] Thanks Jon, That works a treat but how exactly does that work..? Why are there reference to 3 ROWLABELS? Trying to understand how that function requires its arguments as it can be very useful but also is quite complicated... On 7 January 2015 at 18:30, Jon K Peck <peck@...> wrote: How about this: SPSSINC MODIFY TABLES subtype="customtable" DIMENSION= COLUMNS PROCESS = PRECEDING /WIDTHS ROWLABELS = 0 1 2 ROWLABELWIDTHS=0 0 0 /STYLES APPLYTO=LABELS. Jon Peck (no "h") aka Kim Senior Software Engineer, IBM peck@... phone: 720-342-5621 From: Jignesh Sutar <jsutar@...> To: [hidden email] Date: 01/07/2015 11:11 AM Subject: Re: [SPSSX-L] How to populate blank row header labels Sent by: "SPSSX(r) Discussion" <[hidden email]> A hack I use is to nest the original nesting variables twice: ie: get file="C:\Program Files\IBM\SPSS\Statistics\22\Samples\English\Employee data.sav". set tvars=labels tnumbers=labels. ctables /vlabels variables=gender educ display=none /table (gender>educ)[c] /categories variables=all empty=exclude. ctables /vlabels variables=gender educ display=none /table (gender>educ>gender>educ)[c] /categories variables=all empty=exclude. <http://spssx-discussion.1045642.n5.nabble.com/file/n5728366/Capture.png> This then produces the repeated labels but all that is left to do then is delete the additional/redundant columns. Note this will work only for counts, if then attempting to extract column %, it will give 100% in each row... *Jon*, I tried deleting those redundant columns to the left using below but I don't know how to reference the label columns, it only reference starting from the data columns: SPSSINC MODIFY TABLES subtype="customtable" SELECT=-1 DIMENSION= columns LEVEL = -1 PROCESS = PRECEDING HIDE=TRUE /STYLES APPLYTO=BOTH. Also, could SPSSINC MODIFY TABLES be used to fill in those blank labels for nested cells instead of this double nesting approach? -- View this message in context: http://spssx-discussion.1045642.n5.nabble.com/How-to-populate-blank-row-header-labels-tp5715908p5728366.html Sent from the SPSSX Discussion mailing list archive at Nabble.com. ===================== To manage your subscription to SPSSX-L, send a message to LISTSERV@... (not to SPSSX-L), with no body text except the command. To leave the list, send the command SIGNOFF SPSSX-L For a list of commands to manage subscriptions, send the command INFO REFCARD ===================== To manage your subscription to SPSSX-L, send a message to LISTSERV@... (not to SPSSX-L), with no body text except the command. To leave the list, send the command SIGNOFF SPSSX-L For a list of commands to manage subscriptions, send the command INFO REFCARD ===================== To manage your subscription to SPSSX-L, send a message to [hidden email] (not to SPSSX-L), with no body text except the command. To leave the list, send the command SIGNOFF SPSSX-L For a list of commands to manage subscriptions, send the command INFO REFCARD |
| Free forum by Nabble | Edit this page |