Input Data


|
Hello
I write my thesis about the quality of hospitals. Now, I found a dataset about the patientsatisfaction (surveys). The output is set in % and the % on each question. So, my rows exists of the hospitals, the columns are the answers. Example: "% of patients who think the room was clean enough - always" "% of paitenst who think the room was clean enough" - sometimes" "% of paitenst who think the room was clean enough" - never" And so on for the other questions. How do I have to work with these data in SPSS? I wanted to make a regressionanalysis, but do I have to define these output items as "multiple response" - thing? Or can I just work with them seperately? Thanks! |
|
|
I'm sorry, I mean 'patients'
|
|
Administrator
|
In reply to this post by LiesVW
What is it that you expect to learn from these data?
It sounds like it is all aggregated. Hardly appropriate for Regression. Doesn't sound like what you have found is even applicable to cross tabulation since what you describe are merely marginal distributions. Maybe try to locate different data and formulate a research hypothesis. Can't make a silk purse out of a sow's ear my friend.
Please reply to the list and not to my personal email.
Those desiring my consulting or training services please feel free to email me. --- "Nolite dare sanctum canibus neque mittatis margaritas vestras ante porcos ne forte conculcent eas pedibus suis." Cum es damnatorum possederunt porcos iens ut salire off sanguinum cliff in abyssum?" |
|
|
In reply to this post by LiesVW
Do you have a data set in SPSS *.sav or Excel *.xls or *.xlsx format. If not, as David says, you can't do anything with SPSS. If you do have a data set, I'd stick to frequencies and cross-tabulations. Have a look at my website, starting on page “SPSS Without Tears” www.surveyresearch.weebly.com/spss-without-tears.html John F Hall (Mr) [Retired academic survey researcher] Email: [hidden email] Website: www.surveyresearch.weebly.com -----Original Message----- Hello I write my thesis about the quality of hospitals. Now, I found a dataset about the patientsatisfaction (surveys). The output is set in % and the % on each question. So, my rows exists of the hospitals, the columns are the answers. Example: "% of patients who think the room was clean enough - always" "% of paitenst who think the room was clean enough" - sometimes" "% of paitenst who think the room was clean enough" - never" And so on for the other questions. How do I have to work with these data in SPSS? I wanted to make a regressionanalysis, but do I have to define these output items as "multiple response" - thing? Or can I just work with them seperately? Thanks! -- View this message in context: http://spssx-discussion.1045642.n5.nabble.com/Input-Data-tp5719569.html Sent from the SPSSX Discussion mailing list archive at Nabble.com. ===================== To manage your subscription to SPSSX-L, send a message to [hidden email] (not to SPSSX-L), with no body text except the command. To leave the list, send the command SIGNOFF SPSSX-L For a list of commands to manage subscriptions, send the command INFO REFCARD |
|
|
In reply to this post by LiesVW
First: I think David and John are forgetting about the possibilities
of "evaluation research"; if you want to compare and analyze the features of hospitals, it is feasible to start with data of this sort on hospitals. What do you do with these numbers? The simple and direct approach, which I think should be the first approach, is to convert those percentages (for "Clean", and for other items) into a single score for each topic. Thus, by scoring (Never=1, Sometimes=2, Always=3) and multiplying by the percentage fractions, you recover an average-item score for each hospital. Then you end up with a data set where Hospital has the role that we usually think of for Subject; and you have a set of item scores. From a set of item scores, when there are a lot of items, the immediate process of "data reduction" is one of creating a reduced set of scores. If there are not obvious scales (composite scores), then you may use factor analysis to derive latent factors. One way or another, your aim is to end up with maybe 6 to 10 items about "Physical environment" (including Clean) for which you compute an average score. But doing a factor analysis is getting into a somewhat advanced process for a beginner on a limited project -- You may be better off if you can create some arbitrary scales of intuitive value. These are your "outcome values" for whatever comparisons are to be done. The simplest study might be exploratory: What are the averages that are observed? - It could be alarming, for instance, if there were a very low average score for how "Clean" hospitals were rated by their patients. - But comparisons can be more interesting. It is somewhat interesting that 80% of patients are "pretty satisfied" with their care for a hospital stay; it is more interesting to learn that V.A. hospitals, practicing the closest thing the U.S. has to "socialized medicine", receive higher satisfaction scores than other U.S. hospitals. Now, you have some hospital characteristics that you may consider for whether they are associated with your outcomes. You should have some hypotheses in mind; or why are you looking at these data? You should state your two or three main hypotheses in advance, and try to figure out how to state them clearly and unambiguously; that is not always easy. -- Rich Ulrich > Date: Fri, 19 Apr 2013 11:48:51 -0700 > From: [hidden email] > Subject: Input Data > To: [hidden email] > > Hello > > I write my thesis about the quality of hospitals. Now, I found a dataset > about the patientsatisfaction (surveys). The output is set in % and the % on > each question. So, my rows exists of the hospitals, the columns are the > answers. > > Example: > "% of patients who think the room was clean enough - always" > "% of paitenst who think the room was clean enough" - sometimes" > "% of paitenst who think the room was clean enough" - never" > > And so on for the other questions > > How do I have to work with these data in SPSS? > I wanted to make a regressionanalysis, but do I have to define these > output items as "multiple response" - thing? Or can I just work with them > seperately? > > Thanks! > ... |
|
|
This post was updated on .
In reply to this post by LiesVW
CONTENTS DELETED
The author has deleted this message.
|
|
Administrator
|
Look at VARSTOCASES command. That will get your data into 1 column per '3 options' .
Please reply to the list and not to my personal email.
Those desiring my consulting or training services please feel free to email me. --- "Nolite dare sanctum canibus neque mittatis margaritas vestras ante porcos ne forte conculcent eas pedibus suis." Cum es damnatorum possederunt porcos iens ut salire off sanguinum cliff in abyssum?" |

|
|
Hi
I am not in the office right now - I will be back Monday April 29th and respond to your mail
Best regards Søren
|
|
|
In reply to this post by Rich Ulrich
Yes, I want to put the three 'options' at each question into one variable,
like 'Cleanness' and so on. I have a book about SPSS and there's an explanation about 'multiple response' but when the input is different, so that you only have '1' , '2' or '3' as 'answers'. But I can't work with that method, do I? So do I have to multiply the percentages with 'a degree of satisfaction'? Like, 0,80*1? But then I still have three 'suboutcomes' at each variable. Can I work with those data? And how do I define these variables in SPSS, like 'Cleanness'? -- View this message in context: http://spssx-discussion.1045642.n5.nabble.com/Input-Data-tp5719569p5719585.html Sent from the SPSSX Discussion mailing list archive at Nabble.com. ===================== To manage your subscription to SPSSX-L, send a message to [hidden email] (not to SPSSX-L), with no body text except the command. To leave the list, send the command SIGNOFF SPSSX-L For a list of commands to manage subscriptions, send the command INFO REFCARD |
|
|
In reply to this post by LiesVW
Hello!
First of all, thank you everybody for your answers and time! I'm a Belgian student at the Free University of Brussels. If I make any spelling mistakes, I' already apologize for that. With the data, I want to analyse if there's a difference in the care that hospitals give in the US. I analyze 3 kind of hospitals: profit (private), non-profit (public) and private hospitals. The two basic research questions are: "Private hospitals give a better quality of care to their patients than public hospitals." "Private profit hospitals give less quality of care than public and non-profit hospitals." @Rich Ulrich, yes, I want to put the three 'options' at each question into one variable, like 'Cleanness' and so on. I have a book about SPSS and there's an explanation about 'multiple response' but when the input is different, so that you only have '1' , '2' or '3' as 'answers'. But I can't work with that method, do I? So do I have to multiply the percentages with 'a degree of satisfaction'? Like, 0,80*1? But then I still have three 'suboutcomes' at each variable. Can I work with those data? And how do I define these variables in SPSS, like 'Cleanness'? There's a question "Would you recommend the hospital?" -> 'Yes, absolutely' , 'Yes, probably' and 'No' and that would be my indicator. When I know which hospital type provide the best quality (I think I can get an answer by just seeing which hospital type gets the most 'Yes, absolutely' as answer, but I just don't know if the input in % is okay the way it is now), I want to make a regressionanalysis (if possible) to see which variables are the most correlated to the recommend of the hospital and if the definition of good quality differs between the hospital types (according to the patients). Is it possible? I will make an image of my excel file! Thanks again everyone! 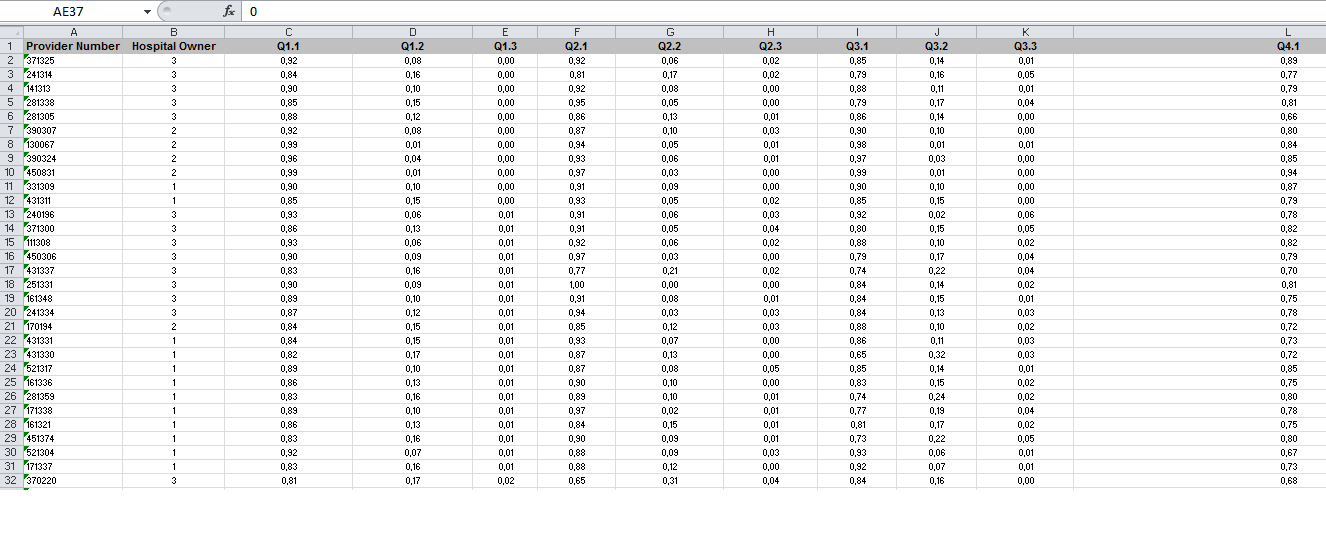
|
|
|
In reply to this post by David Marso
Thank you!
I searched that command on the internet. But is it possible that I lose important information when I put those 3 answers into 1? I'm sorry, but I can't see how this would work, or not immediately. I will try it and keep you up to date. |
|
Administrator
|
eg:. DATA LIST LIST / hinfo q1_1 to q1_3 q2_1 to q2_3 . BEGIN DATA 1 1.11 1.12 1.13 1.21 1.22 1.23 2 2.11 2.12 2.13 2.21 2.22 2.23 END DATA. VARSTOCASES /ID = id /MAKE Q1 FROM q1_1 TO q1_3 /MAKE Q2 FROM q2_1 TO q2_3 /INDEX = Index1(3) /KEEP = hinfo. LIST. ID HINFO INDEX1 Q1 Q2 1 1.00 1 1.11 1.21 1 1.00 2 1.12 1.22 1 1.00 3 1.13 1.23 2 2.00 1 2.11 2.21 2 2.00 2 2.12 2.22 2 2.00 3 2.13 2.23 Number of cases read: 6 Number of cases listed: 6
Please reply to the list and not to my personal email.
Those desiring my consulting or training services please feel free to email me. --- "Nolite dare sanctum canibus neque mittatis margaritas vestras ante porcos ne forte conculcent eas pedibus suis." Cum es damnatorum possederunt porcos iens ut salire off sanguinum cliff in abyssum?" |
|
|
Okay!
The information I got from the internet tells me to work with 'Data -> Restructure...' Is it the same? |
|
|
Is this the command that I can use?
http://psychology.clas.asu.edu/files/FittingmultilevelmodelsusingSPSSpull-downs.pdf |
|
|
In reply to this post by Rich Ulrich
Thank you!
To start, I will make those scores for the type of hospitals! So I have to multiply the outputs (%) with the scores en then make the sum of them? So that every hospital will have a score at 3? Example: 0.08 * 1 + 0.12 * 2 + 0.80 * 3 = 2.72? |
|
Administrator
|
In reply to this post by LiesVW
If you are referring to David's suggestion to use VARSTOCASES, then yes, you can use the Data > Restructure dialog to paste VARSTOCASES syntax.
--
Bruce Weaver bweaver@lakeheadu.ca http://sites.google.com/a/lakeheadu.ca/bweaver/ "When all else fails, RTFM." PLEASE NOTE THE FOLLOWING: 1. My Hotmail account is not monitored regularly. To send me an e-mail, please use the address shown above. 2. The SPSSX Discussion forum on Nabble is no longer linked to the SPSSX-L listserv administered by UGA (https://listserv.uga.edu/). |
|
|
In reply to this post by LiesVW
Hmmm. A thesis, huh? And you have come to SPSS-L with a vague question about performing a regression analysis, without any hint of an actual research question.
So, we are supposed to solve all data structuring, psychometric, and analytic issues in order to help you arrive at some unspecified regression analysis. Shall we devise your research questions for you, as well? A thesis should be to synthesize much of what you have learned during your formal education into a real-world study. Obviously if you have a specific SPSS question or even a specific statistical question as it relates to SPSS, I would be more inclined to help. But the message I just read is no where near what is acceptable for me to provide any assistance on this forum. As I will continue to say to students, go to your research advisor for guidance. Ryan On Apr 19, 2013, at 2:48 PM, LiesVW <[hidden email]> wrote: > Hello > > I write my thesis about the quality of hospitals. Now, I found a dataset > about the patientsatisfaction (surveys). The output is set in % and the % on > each question. So, my rows exists of the hospitals, the columns are the > answers. > > Example: > "% of patients who think the room was clean enough - always" > "% of paitenst who think the room was clean enough" - sometimes" > "% of paitenst who think the room was clean enough" - never" > > And so on for the other questions. > > How do I have to work with these data in SPSS? > I wanted to make a regressionanalysis, but do I have to define these > output items as "multiple response" - thing? Or can I just work with them > seperately? > > Thanks! > > > > -- > View this message in context: http://spssx-discussion.1045642.n5.nabble.com/Input-Data-tp5719569.html > Sent from the SPSSX Discussion mailing list archive at Nabble.com. > > ===================== > To manage your subscription to SPSSX-L, send a message to > [hidden email] (not to SPSSX-L), with no body text except the > command. To leave the list, send the command > SIGNOFF SPSSX-L > For a list of commands to manage subscriptions, send the command > INFO REFCARD ===================== To manage your subscription to SPSSX-L, send a message to [hidden email] (not to SPSSX-L), with no body text except the command. To leave the list, send the command SIGNOFF SPSSX-L For a list of commands to manage subscriptions, send the command INFO REFCARD |
|
|
Thank you
I didn't put all the necessary information into my first message. I have a research question and I do know what I want to do with the data. I just didn't know how to restructure the data, but now I have an aswer to that.
|
|
Administrator
|
Note: If you proceed with the idea of using Sum(Pi * Xi) as a 'mean' response as suggested previously by Rich you are adopting the dubious assumption that the 'measure' is ratio (equal interval etc...).
People do it all the time doesn't make it right! Several decades ago the ideas/seeds of optimal scaling, correspondence analysis and the like were planted but seem not to have not blossomed in the minds of most analysts (I was mucking around in those fields about 25 years ago). My last thoughts on this matter. Good luck with the thesis. http://www.search.ask.com/web?l=dis&o=15555&qsrc=2873&q=Optimal%20scaling I'm now clawing my way out of the rabbit hole. Tea time! Let's see we have Earl Grey, Shroom Boom, a wonderful Emperor Green Tea, Lipton and Hemlock. Toss the dice blindfolded? ---------------------------------------------------------------------------------
Please reply to the list and not to my personal email.
Those desiring my consulting or training services please feel free to email me. --- "Nolite dare sanctum canibus neque mittatis margaritas vestras ante porcos ne forte conculcent eas pedibus suis." Cum es damnatorum possederunt porcos iens ut salire off sanguinum cliff in abyssum?" |
|
|
David, You raise a critically important point, which I was not going to address. However, since you brought it up, I will, at least very briefly discuss this issue. This is where latent trait theory (a.k.a. item response theory) is particularly helpful. If there is a latent variable (construct), then use of IRT modeling, particularly Rasch modeling (e.g., via an adjacent-category logistic regression model), could be used to evaluate the extent to which response options for each item are ordered, the trait level at which there is an equal probability of endorsing adjacent categories (andrich thresholds), and the average trait level for those who responded to that item, all of which are measured on the logit, interval-level scale.
So often I have found through the use of IRT modeling that the average trait level of those who endorse a particular response option for a particular item (e.g. almost always) is lower than the average trait level for a particular response option for that same item which was assumed to be at a lower level (e.g., often); i.e.,
Never=1, Sometimes=2, Rarely=3, Often=4, and Almost Always=5 I have also come across disordered andrich thresholds... This is one of many examples. These diagnostics, if you will, should be evaluated and remedied before analysis, whenever possible.
The point I made above is intrinsically connected to David's point about the assumption of having an interval-level measure; the idea behind a type of Rasch rating scale, for example, is that one need not make such an assumption. In fact, the point is to convert raw scores from an ordinal level scale, at best, to an interval level measure via an adjacent-category regression logistic model, and by doing so, one shines a big bright light on the assumptions (e.g., interval level) built into the original scale, both at the response option level, as well as the item level. There are other related benefits that I do not have time to discuss.
I do appreciate Rich's suggestion, however, depending on the OPs experience with *contemporary* psychometrics as well as access to the data; attempting to convert an ordinal-level scale, at best, to an interval-level measure may not be feasible.
*Taking advantage of the properties of the logit scale is by no means a new idea (George Rasch's original article dates back to 1960), but most theories of measurement textbooks label it as contemporary to distinguish it from Classical Test Theory (CTT).
I'm not sure if this is exactly what David was after, but this seems to be related, at least to some degree. Green tea, no sugar, please. :-) Best, Ryan On Sat, Apr 20, 2013 at 11:34 AM, David Marso <[hidden email]> wrote: Note: If you proceed with the idea of using Sum(Pi * Xi) as a 'mean' response |
| Free forum by Nabble | Edit this page |