Interpreting 2x2 and 2x3 chi-square - some reassurance please!

Interpreting 2x2 and 2x3 chi-square - some reassurance please!

|
Greetings from Ireland all. I am currently working on my master's thesis due in about a month. It looks in part at alcohol use amongst college students in a university, for which I distributed a survey. Most of what the survey examines is descriptive data and was easy to generate in SPSS. However I wanted to briefly examine via chi-square test for independence whether age and gender were related to a measure called the audit-c which basically classifies whether a student is at no risk/at risk of harm from alcohol. I would like your help in interpreting in particular the 2x3 and your reassurance that my interpretation of 2x2 is correct. I have read loads of stats books and looked online but still not getting it, as stats is not my strong point!
1)Output is as follows for the 2x2 table: 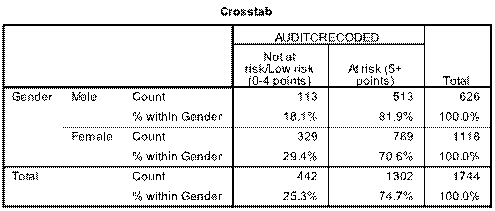 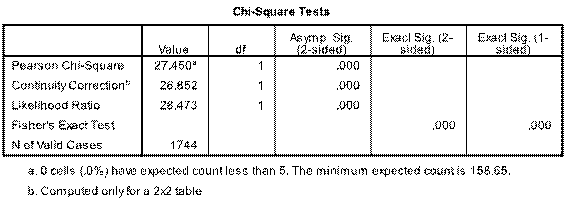 Sorry about poor quality, best I could do - for some reason if you zoom in a bit attachments become clearer. My interpretations as follows: Table x reveals that 74.7% of students emerged as at risk of harm from alcohol. There was a significant difference in positive AUDIT-C scores between males and females (81.9% versus 70.6%, p<0.0001). _______________________________________________________________________________________ 2)This is where it becomes more tricky. Below is 2x3 table - have i interpreted it correctly? As follows: Table x demonstrates that 26.8% of students are at risk of serious harm from alcohol, and 38.1% are at severe risk. Although females scored marginally higher than males in the “At risk” and “High risk” categories, males scored far higher in the severe risk category (55.4% versus 28.4%) whilst the opposite was true for females in the “Not at risk/Low risk” category (29.4% versus 18.1%). This difference was significant at P<0.0001 as reflected in table x. 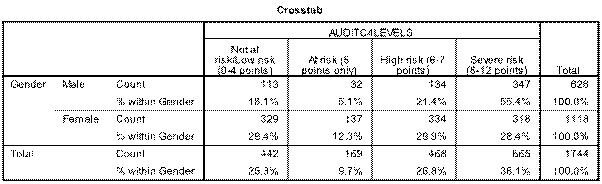 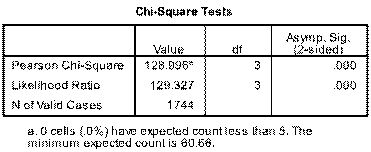 _________________________________________________________________________________________ 3) This examines age and the audit-c measure (whether a student is at no risk/risk). Again unsure if I have interpreted it correctly but here it goes: While there does not appear to be a difference amongst the younger categories (18-20 years and 21-24 years) in terms of a decreasing AUDIT-C score with age, those aged 25 years and above appear to enjoy this benefit. Table x demonstrates that this is a significant finding. 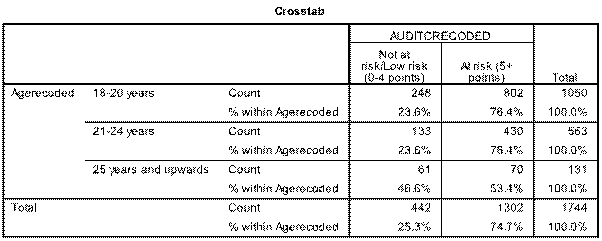 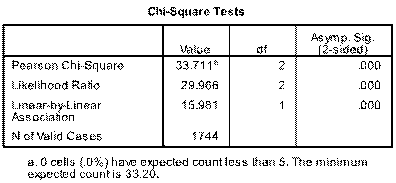 Overall question: Am i correct in assumming that in 2x3 tables or larger that it is not possible to examine specific differences between variables with this measure, only to say that a finding is significant or not (i.e. that there is some form of a difference or not?), where is in 2x2 you can say what this difference appears to be? Really appreciate anyone who can help me out. Thanks so much Tom |
Re: Interpreting 2x2 and 2x3 chi-square - some reassurance please!
|
|
Tom
Left it a bit late, haven't you? How do you
know your sample is representative of the population from which it is
drawn? If not, there's no point at all in using inferential
statistics. Why bother with grouped scores
when you can use a t-test (or analysis of variance if you're comparing more than
one group) on the raw ones? Who is you supervisor? Send him/her off
for re-training and tell him/her to ease off on the booze! Mind you,
N = 1700+ is a nice big "sample" to play with.
John Hall
One-time External Examiner for Ulster Polytechnic
CNAA Masters' degrees (and I said the same then, but more about the
standards than the stats. My 2nd year undergrads did better stuff, but I
got bollocked by the other Examiner, Prof Rcichard Brown, Durham, for being
too honest in my report to CNAA, which I stand by to this day. Needless to
say, I resigned from CNAA duities as soon as my 3-year tour of duty was over:
who wants to work a 14-hour day via the Heathrow Shuttle for peanuts, you get
stopped by armed patrols, and the only cheese you get in the restaurant is
Cheddar? Decent wine? Forget it, unless things have changed
since.)
----- Original Message -----
|
Re: Interpreting 2x2 and 2x3 chi-square - some reassurance please!
|
Administrator
|
In reply to this post by underpressure
--- snip the rest --- Tom, I am not familiar with audit-c, but it appears to yield a score from 0-12, with higher scores indicating higher risk, is that right? Is it fair to assume that it has at least approximate interval scale properties? I.e., does a one-point increase indicate approximately the same change in risk at any point along the scale? And would it be reasonable to use means & SDs descriptively for the audit-c? If the answer is YES to both questions, then I wonder why you are not treating it as a continuous variable in your analyses. Why are you not running a linear regression model with both age (as continuous) and sex as predictors, and perhaps their interaction? Your sample size certainly looks large enough to support this kind of model. HTH.
--
Bruce Weaver bweaver@lakeheadu.ca http://sites.google.com/a/lakeheadu.ca/bweaver/ "When all else fails, RTFM." PLEASE NOTE THE FOLLOWING: 1. My Hotmail account is not monitored regularly. To send me an e-mail, please use the address shown above. 2. The SPSSX Discussion forum on Nabble is no longer linked to the SPSSX-L listserv administered by UGA (https://listserv.uga.edu/). |
Re: Interpreting 2x2 and 2x3 chi-square - some reassurance please!
|
|
Hi Bruce, thanks for your reply. You are correct in that the minimum someone can score is 0 points and 12 the maximum. However it is not scaled (if that is correct term) in that a one point increase does not equal the same change in risk. For the sake of ease in the basic 2x2 (and because several irish studies have done similar), someone scoring between 0-4 has a no to low risk of alcohol harm, where as someone getting 5 or above is at risk. However someone getting say a 4 is not twice as much at risk as someone getting a 2, they just fall under that category (hope this makes sense). Internationally it is agreed however that people scoring between 6-7 are at high risk and those scoring 8-12 at severe risk but some who gets 12 does not have double the risk of 6.
The other reason I am using this method is that it is a taught master's thesis (so this thesis makes up about 35-40% of overall masters as modules make up rest) and the fact that there is a large qualitative component that examines the health services on campus, as well as other questions aimed at students such as their agreement with various statements, level of drink-driving, open-ended questions etc. and all this with only a 10,000 word count so limited in terms of space. One of the main things I wanted to do anyway was just to see what proportion of the population actually met the Audit-C criteria which I have done. I just wanted to use chi-square to examine briefly any potential associations. Thanks Tom On Thu, Jul 29, 2010 at 1:44 PM, Bruce Weaver [via SPSSX Discussion] <[hidden email]> wrote:
|
Re: Interpreting 2x2 and 2x3 chi-square - some reassurance please!
|
Administrator
|
To say that 12 reflects twice as much risk (or twice as much whatever) would require a ratio scale--i.e., a scale with a true 0. Interval scales only require that a change of x units reflects the same amount of change in risk (or whatever) at any point along the scale. But from what you've said, Audit-c does not even meet that criterion. OK then, so you have several categories of risk, and they are ordered (from lowest to highest). You also have a large sample. Your explanatory variables are sex and age. Again, the age categories are ordered. So one option is to take advantage of the ordinal nature of your categories by looking at the test of linear-by-linear association you get in the table of chi-square output. You can read about it here: http://www.uvm.edu/~dhowell/methods7/Supplements/OrdinalChiSq.html The title says something about missing data, but that is just a typo. HTH.
--
Bruce Weaver bweaver@lakeheadu.ca http://sites.google.com/a/lakeheadu.ca/bweaver/ "When all else fails, RTFM." PLEASE NOTE THE FOLLOWING: 1. My Hotmail account is not monitored regularly. To send me an e-mail, please use the address shown above. 2. The SPSSX Discussion forum on Nabble is no longer linked to the SPSSX-L listserv administered by UGA (https://listserv.uga.edu/). |
Re: Interpreting 2x2 and 2x3 chi-square - some reassurance please!
|
|
In reply to this post by underpressure
I would suggest 1) do exploratory graphics as if the data were
continuous, i.e., boxplots for all SES * SES variable groups, and
for� � values on each of the marginal SES variables, and for all
cases. Try a 3D scatterplot, you can use color to add a fourth
variable.
2) see how an ordinary regression looks with the SES variables as predictors 4) use� categorical regression with the SES variables as predictors with a 0-12 value DV. See if measurement level (ordinal vs interval) is important. 5) use categorical regression on a coarsened dv (0 to 4 =1) etc. See if measurement level (ordinal vs interval) is important. If the unusual happens and coarsening the DV does not distort the picture, go ahead with the coarsened DV. Mention that more refined measurement did not change the substantive conclusions. Art Kendall Social Research Consultants On 7/29/2010 8:53 AM, SPSSassasin wrote: Hi Bruce, thanks for your reply. You are correct in that the minimum someone can score is 0 points and 12 the maximum. However it is not scaled (if that is correct term) in that a one point increase does not equal the same change in risk. For the sake of ease in the basic 2x2 (and because several irish studies have done similar), someone scoring between 0-4 has a no to low risk of alcohol harm, where as someone getting 5 or above is at risk. However someone getting say a 4 is not twice as much at risk as someone getting a 2, they just fall under that category (hope this makes sense). Internationally it is agreed however that people scoring between 6-7 are at high risk and those scoring 8-12 at severe risk but some who gets 12 does not have double the risk of 6.===================== To manage your subscription to SPSSX-L, send a message to [hidden email] (not to SPSSX-L), with no body text except the command. To leave the list, send the command SIGNOFF SPSSX-L For a list of commands to manage subscriptions, send the command INFO REFCARD
Art Kendall
Social Research Consultants |
«
Return to SPSSX Discussion
|
1 view|%1 views
| Free forum by Nabble | Edit this page |