Mean score for a directed relationship

Mean score for a directed relationship

|
I have for each respondent a judgement on the trust in six partner organisations. I would like to get the mean score of respondents from one organisations about the other organisation. I did the calculations through excel but I would like to check back with SPSS whether I did not mess up somewhere.
So I would like to see what the mean trust score was from people from org. 1 about org 2, 3, 4, 5 and 6. And then also for respondents from org 2 about 1, 3, 4, 5, 6, and so on. Ideally, I would also like to see how many values were used to calculate the mean. I added a screenshot of a simplified dataset for clarification. 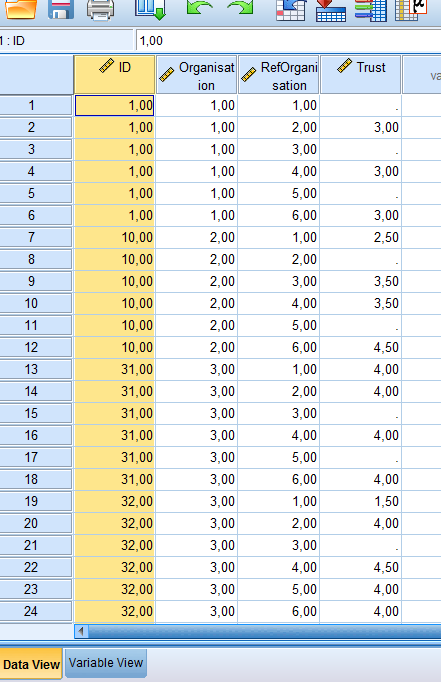
|
Re: Mean score for a directed relationship
|
Administrator
|
Very simple with AGGREGATE command. Look it up.
Please reply to the list and not to my personal email.
Those desiring my consulting or training services please feel free to email me. --- "Nolite dare sanctum canibus neque mittatis margaritas vestras ante porcos ne forte conculcent eas pedibus suis." Cum es damnatorum possederunt porcos iens ut salire off sanguinum cliff in abyssum?" |
|
|
In reply to this post by Sarah Deweert
I don't completely understand what you are saying below
but this is what I can infer: (1) A respondent (say ID= 001) is a member of an organization and this organization is represented by the variable "organization". It might be better to call this "respondent's organization" or respondent_org for brevity. (I assume you use commas instead of dots/periods because of where you're doing the analysis; I will use dots/periods instead). (2) I don't understand what a "judgment on trust" is (a rating on a 5-point rating scale?) but such a judgment is made about 6 organizations that includes the organization that the respondent is a member of. Is this correct? This appears to be represented by the variable RefOrganization -- it might be better to call this "Target Organization" or target_org or even judged_org to make clear that it contains the values identifying the organization being judged. Why a respondent doesn't provide a trust value for all reforgs is unclear. (3) I'm not sure but I guess that "Target" is some sort of rating a person makes about an organization? For ID=001, this person gave RefOrganisation=2.00 a value for Trust=3.00, for RefOrg= 4.00 Trust=3.00, and for RefOrg=6.00 Trust=3.00. Other cases have a value for Trust such as 3.50 and I'll assume this is a valid single number (instead of a mean=3.50). (4) A simple (oversimplified?) way to get what you want is to use the Mean procedure: means table= trust by organization by RefOrganization/ cells= mean, count. This will produce a table where Column 1 contains the values of Organization (1-6) Column 2 contains the values of RefOrganization (1-6) for each level of Organization in column 1. Column 3 contains the mean of Trust Column 4 contains the number of values (N) used in the computation of the mean. (5) A "Crossbreak" or crosstabulation would be a more compact representation of the results but, alas, SPSS did away with the Crossbreak subcommand in the Means procedure. You can get a crossbreak table in the CTABLE or Custom Tables procedure. So, if we put levels of Organization in the rows and RefOrganization in the columns of the table, then we can put the mean of Trust and number of values used. Try the following: ctables /vlabels variables= organization, reforganization, trust Display=both /table organization by reforganization by trust [mean, count f40.2] /categories variables= organization,reforganization Order=A Key=value empty=include. I don't use ctables much, so if anyone finds an error or can be made prettier, let me know. Then again, I could be misunderstanding the situation in which case, nevermind. ;-) -Mike Palij New York University [hidden email] ----- Original Message ----- On Friday, October 28, 2016 9:35 AM, Sarah Deweert wrote: >I have for each respondent a judgement on the trust in six partner > organisations. I would like to get the mean score of respondents from > one > organisations about the other organisation. I did the calculations > through > excel but I would like to check back with SPSS whether I did not mess > up > somewhere. > > So I would like to see what the mean trust score was from people from > org. 1 > about org 2, 3, 4, 5 and 6. And then also for respondents from org 2 > about > 1, 3, 4, 5, 6, and so on. Ideally, I would also like to see how many > values > were used to calculate the mean. > > I added a screenshot of a simplified dataset for clarification. > > <http://spssx-discussion.1045642.n5.nabble.com/file/n5733410/table_spssx.png> ===================== To manage your subscription to SPSSX-L, send a message to [hidden email] (not to SPSSX-L), with no body text except the command. To leave the list, send the command SIGNOFF SPSSX-L For a list of commands to manage subscriptions, send the command INFO REFCARD |
Re: Mean score for a directed relationship
|
|
Your simple method of the means procedure already does the trick. Thank you very much! The CTABLE command worked perfectly as well, so no errors there, but for now I like the oversight of the means command better.
For more background on the data, you did figure out everything correctly. I am also grateful for the tips on renaming the variables for clarity reasons. The judgements are actually the mean of a series of judgements on the ability, benevolence and integrity of the members of the other organisation. It is the sum of six judgements (items in the questionnaire) on a 5-point scale, divided by six. As I remember this is a valid way to make an aggregated variable. There is indeed a judgement by one respondent for each of the six organisations, including his own, in the dataset. But for his own organisation there will always be a missing, because no respondent judges his own organisation. The data looks like this because this was the easiest for me to restructure the data. Concerning the missing judgements for some target organisations, this is mostly due to not having contact with that organisation, so the question was not applicable. |
«
Return to SPSSX Discussion
|
1 view|%1 views
| Free forum by Nabble | Edit this page |