delete duplicate brand names in the concatenated variable

12

12
delete duplicate brand names in the concatenated variable

|
There are 4 variables data i.e. from Var1 to Var4 in SPSS file. From these variables I am trying to concatenate and creating a new variable with name “Brand_Main”. Below is the SPSS code.
DEFINE MRMAC (START = !CHAREND("/") / END = !CHAREND("/") / X = !TOKENS(1) /nbval=!TOKENS(1)). string !X(a2500). do repeat var = !START to !END. if char.length(rtrim(!X)) ne 0 and char.length(valuelabels(var)) gt 0 !X = concat(rtrim(!X),';',valuelabels(var)). if char.length(rtrim(!X)) = 0 !X = valuelabels(var). end repeat. !ENDDEFINE. MRMAC START = Var1 / END = Var4 / X = Brand_Main. However, when I do so I could observe that there are few brands that are identical across the cases and I would like to delete those duplicate brand names in the concatenated variable i.e. “Brand_Main” and keep only the non-duplicate onces. so finally data should be in the same way as variable “Brand_Final” – (which I have manually created it by deleting the duplicates). Please help in getting the syntax to do the mentioned task.  Sample_data.sav |
|
|
Here is a python solution.
******************************. SPSSINC GETURI DATA URI="http://spssx-discussion.1045642.n5.nabble.com/file/n5729898/Sample_data.sav" FILETYPE=SAV DATASET=Samp. BEGIN PROGRAM Python. #unique function adapted via http://www.peterbe.com/plog/uniqifiers-benchmark (f5) def UniqueList(x,str): seen = {} result = [] for item in x: if item in seen: continue seen[item] = 1 if item.strip() != '': result.append(item) return str.join(result) END PROGRAM. *Now use SPSSINC TRANS to call the function. SPSSINC TRANS RESULT=Brand_Final2 TYPE=20 /VARIABLES Var1 TO Var4 /FORMULA "UniqueList(x=[<>],str=''';''')". ******************************. The function would be a bit simpler if the original ordering of the variables need not be preserved (so one can use sets in Python to get the unique elements). A native SPSS solution might involve VARSTOCASES to eliminate duplicates. Another way would be to iterate over the list in a set of nested loops, something like below (untested): VECTOR V = Var1 TO Var4. LOOP #i = 1 TO 3. LOOP #j = (#i + 1) TO 4. IF V(#i) = V(#j) V(#j) = "". END LOOP. END LOOP. But to accommodate this via a macro one would either need to change how the parameters are entered via the macro, or compute a bunch of other superfluous stuff. |
Re: delete duplicate brand names in the concatenated variable
|
|
* Hi, something like this should work GL, Mario. STRING brandlist (A90). COMPUTE brandlist = "". IF (CHAR.INDEX(brandlist,var1) EQ 0) brandlist = CONCAT(brandlist,var1,";"). IF (CHAR.INDEX(brandlist,var2) EQ 0) brandlist = CONCAT(brandlist,var2,";"). IF (CHAR.INDEX(brandlist,var3) EQ 0) brandlist = CONCAT(brandlist,var3,";"). IF (CHAR.INDEX(brandlist,var4) EQ 0) brandlist = CONCAT(brandlist,var4,";"). EXECUTE. Andy W <[hidden email]> schrieb am 15:10 Dienstag, 23.Juni 2015: Here is a python solution. ******************************. SPSSINC GETURI DATA URI="http://spssx-discussion.1045642.n5.nabble.com/file/n5729898/Sample_data.sav" FILETYPE=SAV DATASET=Samp. BEGIN PROGRAM Python. #unique function adapted via http://www.peterbe.com/plog/uniqifiers-benchmark (f5) def UniqueList(x,str): seen = {} result = [] for item in x: if item in seen: continue seen[item] = 1 if item.strip() != '': result.append(item) return str.join(result) END PROGRAM. *Now use SPSSINC TRANS to call the function. SPSSINC TRANS RESULT=Brand_Final2 TYPE=20 /VARIABLES Var1 TO Var4 /FORMULA "UniqueList(x=[<>],str=''';''')". ******************************. The function would be a bit simpler if the original ordering of the variables need not be preserved (so one can use sets in Python to get the unique elements). A native SPSS solution might involve VARSTOCASES to eliminate duplicates. Another way would be to iterate over the list in a set of nested loops, something like below (untested): VECTOR V = Var1 TO Var4. LOOP #i = 1 TO 3. LOOP #j = (#i + 1) TO 4. IF V(#i) = V(#j) V(#j) = "". END LOOP. END LOOP. But to accommodate this via a macro one would either need to change how the parameters are entered via the macro, or compute a bunch of other superfluous stuff. ----- Andy W [hidden email] http://andrewpwheeler.wordpress.com/ -- View this message in context: http://spssx-discussion.1045642.n5.nabble.com/delete-duplicate-brand-names-in-the-concatenated-variable-tp5729898p5729901.html Sent from the SPSSX Discussion mailing list archive at Nabble.com. ===================== To manage your subscription to SPSSX-L, send a message to [hidden email] (not to SPSSX-L), with no body text except the command. To leave the list, send the command SIGNOFF SPSSX-L For a list of commands to manage subscriptions, send the command INFO REFCARD
Mario Giesel
Munich, Germany |
Re: delete duplicate brand names in the concatenated variable
|
Administrator
|
Here's a more scalable variation on Mario's theme.
STRING brandlist (A90). DO REPEAT v = var1 to var4. - DO IF LENGTH(v) GT 0. /* Needed to avoid warnings in output. - IF CHAR.INDEX(brandlist,v) EQ 0 brandlist = CONCAT(brandlist,v,";"). - END IF. END REPEAT. * Remove the final semi-colon. COMPUTE brandlist = RTRIM(brandlist,";"). LIST brand_final brandlist. OUTPUT: Brand_Final brandlist Brand3;Brand2 Brand3;Brand2 Brand2;Brand3 Brand2;Brand3 Brand1;Brand2;Brand3 Brand1;Brand2;Brand3 Brand1;Brand3 Brand1;Brand3 Brand1;Brand2;Brand4 Brand1;Brand2;Brand4 Brand1;Brand2;Brand3 Brand1;Brand2;Brand3 Brand1;Brand3 Brand1;Brand3 Brand1;Brand2Brand4 Brand1;Brand2;Brand4 Brand1;Brand2;Brand3 Brand1;Brand2;Brand3 Brand2;Brand3 Brand2;Brand3 Brand2 Brand2
--
Bruce Weaver bweaver@lakeheadu.ca http://sites.google.com/a/lakeheadu.ca/bweaver/ "When all else fails, RTFM." PLEASE NOTE THE FOLLOWING: 1. My Hotmail account is not monitored regularly. To send me an e-mail, please use the address shown above. 2. The SPSSX Discussion forum on Nabble is no longer linked to the SPSSX-L listserv administered by UGA (https://listserv.uga.edu/). |
Re: delete duplicate brand names in the concatenated variable
|
|
If the data for var1 to var4 were the result of manual data entry, you might want to first check for variations in spelling, casing, and spacing.
Autorecode ... /group.
Art Kendall
Social Research Consultants |
Re: delete duplicate brand names in the concatenated variable
|
|
Also, If I Recall Correctly , you would need numeric values for MULT RESPONSE.
Is there any substantive meaning to the order of responses or to multiple mentions of a brand?
Art Kendall
Social Research Consultants |
Re: delete duplicate brand names in the concatenated variable
|
Administrator
|
In reply to this post by Bruce Weaver
What if the original data are
brand11 brand20 brand1 brand2 ;-) brand1 and brand2 will be discarded by the INDEX query. Might want to protect that with IF INDEX(brandlist,CONCAT(v,';')) EQ 0 brandlist=CONCAT(brandlist(v,';')
Please reply to the list and not to my personal email.
Those desiring my consulting or training services please feel free to email me. --- "Nolite dare sanctum canibus neque mittatis margaritas vestras ante porcos ne forte conculcent eas pedibus suis." Cum es damnatorum possederunt porcos iens ut salire off sanguinum cliff in abyssum?" |
Re: delete duplicate brand names in the concatenated variable
|
Administrator
|
Well spotted, and nice fix.
--
Bruce Weaver bweaver@lakeheadu.ca http://sites.google.com/a/lakeheadu.ca/bweaver/ "When all else fails, RTFM." PLEASE NOTE THE FOLLOWING: 1. My Hotmail account is not monitored regularly. To send me an e-mail, please use the address shown above. 2. The SPSSX Discussion forum on Nabble is no longer linked to the SPSSX-L listserv administered by UGA (https://listserv.uga.edu/). |
Re: delete duplicate brand names in the concatenated variable
|
|
In reply to this post by jagadishpchary
Here is a very simple Python solution.
x, y, z, and w are the variables. type should be the string
size for the result (20 in my example). Duplicates are deleted, and
the values are concatened with a blank separator.
begin program. def f(*args): return " ".join(set(args)) end program. spssinc trans result= brand_main type=20 /formula "f(x,y,z,w)". Jon Peck (no "h") aka Kim Senior Software Engineer, IBM [hidden email] phone: 720-342-5621 From: jagadishpchary <[hidden email]> To: [hidden email] Date: 06/23/2015 04:59 AM Subject: [SPSSX-L] delete duplicate brand names in the concatenated variable Sent by: "SPSSX(r) Discussion" <[hidden email]> There are 4 variables data i.e. from Var1 to Var4 in SPSS file. From these variables I am trying to concatenate and creating a new variable with name “Brand_Main”. Below is the SPSS code. DEFINE MRMAC (START = !CHAREND("/") / END = !CHAREND("/") / X = !TOKENS(1) /nbval=!TOKENS(1)). string !X(a2500). do repeat var = !START to !END. if char.length(rtrim(!X)) ne 0 and char.length(valuelabels(var)) gt 0 !X = concat(rtrim(!X),';',valuelabels(var)). if char.length(rtrim(!X)) = 0 !X = valuelabels(var). end repeat. !ENDDEFINE. MRMAC START = Var1 / END = Var4 / X = Brand_Main. However, when I do so I could observe that there are few brands that are identical across the cases and I would like to delete those duplicate brand names in the concatenated variable i.e. “Brand_Main” and keep only the non-duplicate onces. so finally data should be in the same way as variable “Brand_Final” – (which I have manually created it by deleting the duplicates). Please help in getting the syntax to do the mentioned task. <http://spssx-discussion.1045642.n5.nabble.com/file/n5729898/Untitled.png> Sample_data.sav <http://spssx-discussion.1045642.n5.nabble.com/file/n5729898/Sample_data.sav> -- View this message in context: http://spssx-discussion.1045642.n5.nabble.com/delete-duplicate-brand-names-in-the-concatenated-variable-tp5729898.html Sent from the SPSSX Discussion mailing list archive at Nabble.com. ===================== To manage your subscription to SPSSX-L, send a message to [hidden email] (not to SPSSX-L), with no body text except the command. To leave the list, send the command SIGNOFF SPSSX-L For a list of commands to manage subscriptions, send the command INFO REFCARD ===================== To manage your subscription to SPSSX-L, send a message to [hidden email] (not to SPSSX-L), with no body text except the command. To leave the list, send the command SIGNOFF SPSSX-L For a list of commands to manage subscriptions, send the command INFO REFCARD |
Re: delete duplicate brand names in the concatenated variable
|
|
In reply to this post by jagadishpchary
Thank you all for the wonderful code. However, in my datafile there are some instances like the variables are in String and sometimes in Numeric. So can i have a common code which works on both types.
|
Re: delete duplicate brand names in the concatenated variable
|
Administrator
|
Please see ALTER TYPE command in the FM. Next time it might be a good idea to mention this? On Thu, Jun 25, 2015 at 5:42 AM, jagadishpchary [via SPSSX Discussion] <[hidden email]> wrote: Thank you all for the wonderful code. However, in my datafile there are some instances like the variables are in String and sometimes in Numeric. So can i have a common code which works on both types.
Please reply to the list and not to my personal email.
Those desiring my consulting or training services please feel free to email me. --- "Nolite dare sanctum canibus neque mittatis margaritas vestras ante porcos ne forte conculcent eas pedibus suis." Cum es damnatorum possederunt porcos iens ut salire off sanguinum cliff in abyssum?" |
|
|
In reply to this post by Jon K Peck
Yes, that was what I had in mind when I said using "set" could be simpler. Two things though (that are why my original function was more complicated):
- set does not maintain the original ordering - set does not eliminate empty strings In this example data set always places the empty strings at the end (although I don't know if that will be consistent behavior). So following that function with RTRIM would work, as long as the ordering of the other brands does not matter. |
Re: delete duplicate brand names in the concatenated variable
|
|
In reply to this post by jagadishpchary
For consistency of approach between sets of string variables and sets of numeric variables, consider using AUTORECODE on the string sets
collapsing autorecoded categories if necessary then on both kinds of sets eliminating duplicate entries creating the final string variable by concatenating value labels using the valuelabel function.
Art Kendall
Social Research Consultants |
Re: delete duplicate brand names in the concatenated variable
|
|
In reply to this post by Andy W
If some of the input variables are actually
blank, then one blank value would be included in the output. If that
is a possibility, the blank can be easily eliminated by changing this
begin program. def f(*args): return " ".join(set(args)) end program. spssinc trans result= brand_main type=20 /formula "f(x,y,z,w)". to this begin program. def f(*args): return " ".join(set([s for s in args if not s.strip() == ""])) end program. spssinc trans result= brand_main type=20 /formula "f(x,y,z,w)". Andy, I missed your earlier Python post. Jon Peck (no "h") aka Kim Senior Software Engineer, IBM [hidden email] phone: 720-342-5621 From: Andy W <[hidden email]> To: [hidden email] Date: 06/25/2015 06:32 AM Subject: Re: [SPSSX-L] delete duplicate brand names in the concatenated variable Sent by: "SPSSX(r) Discussion" <[hidden email]> Yes, that was what I had in mind when I said using "set" could be simpler. Two things though (that are why my original function was more complicated): - set does not maintain the original ordering - set does not eliminate empty strings In this example data set always places the empty strings at the end (although I don't know if that will be consistent behavior). So following that function with RTRIM would work, as long as the ordering of the other brands does not matter. ----- Andy W [hidden email] http://andrewpwheeler.wordpress.com/ -- View this message in context: http://spssx-discussion.1045642.n5.nabble.com/delete-duplicate-brand-names-in-the-concatenated-variable-tp5729898p5729942.html Sent from the SPSSX Discussion mailing list archive at Nabble.com. ===================== To manage your subscription to SPSSX-L, send a message to [hidden email] (not to SPSSX-L), with no body text except the command. To leave the list, send the command SIGNOFF SPSSX-L For a list of commands to manage subscriptions, send the command INFO REFCARD ===================== To manage your subscription to SPSSX-L, send a message to [hidden email] (not to SPSSX-L), with no body text except the command. To leave the list, send the command SIGNOFF SPSSX-L For a list of commands to manage subscriptions, send the command INFO REFCARD |
Re: delete duplicate brand names in the concatenated variable
|
|
In reply to this post by jagadishpchary
First of all, I would thank you all for providing the solutions for my post. However, I have considered the SPSS code which “Bruce Weaver” has written.
As per my earlier post, the database which I have considered was “Sample data.sav” in that - all the variables were in string and the provided code is working in the same way as per the plan. Now, I have a new task which I need to get the same results when run on numeric variables. So I modified the code accordingly (Below is the code) DEFINE MRMAC (START = !CHAREND("/") / END = !CHAREND("/") / X = !TOKENS(1) /nbval=!TOKENS(1)). string !X(a2500). do repeat var = !START to !END. IF INDEX(!X,CONCAT(valuelabels(var),';')) EQ 0 !X = CONCAT(!X,valuelabels(var),";"). end repeat. COMPUTE !X = RTRIM(!X,";"). !ENDDEFINE. MRMAC START = Var1 / END = Var4 / X = Brand _Main. EXECUTE. The problem which I am facing is: while concatenating, when the 1st variable is empty the delimiter i.e. “;” is shown as it is – which should be removed. Hence the results should resembl in the same way as “brand_final” (which I have removed the “;” manually) (Attached is the pic). As I am new to SPSS coding - I would request to kindly check my code and let me know the necessary changes to be made in order to get the data as shown in variable “Brand_Final”. FYI – Attached the SPSS data file. 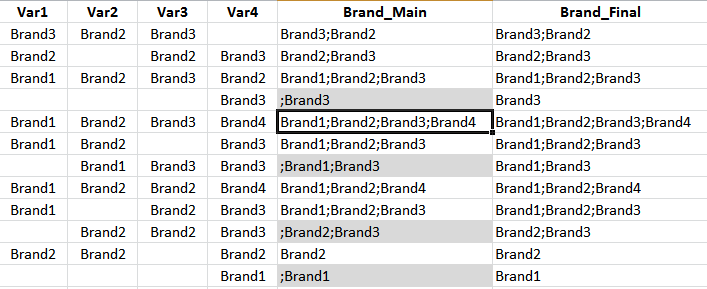 Sample_data_numeric.sav |
Re: delete duplicate brand names in the concatenated variable
|
Administrator
|
Insert
DO IF var NE "". <code> END IF. In the appropriate place. Leaving you scratching your head to discern exactly where to place it after consulting the FM.
Please reply to the list and not to my personal email.
Those desiring my consulting or training services please feel free to email me. --- "Nolite dare sanctum canibus neque mittatis margaritas vestras ante porcos ne forte conculcent eas pedibus suis." Cum es damnatorum possederunt porcos iens ut salire off sanguinum cliff in abyssum?" |

Re: delete duplicate brand names in the concatenated variable
|
Administrator
|
Alternatively, you could do this:
COMPUTE !X = LTRIM(RTRIM(!X,";"),";"). ...instead of this: COMPUTE !X = RTRIM(!X,";"). Also, your macro call has an unwanted space in the middle of variable name Brand_Main. I.e., you have Brand _Main, but want Brand_Main. Finally, unless you have reasons for wanting to retain the A2500 formatting for Brand_Main, you might consider inserting this line at the end of your macro: ALTER TYPE !X (AMIN). HTH.
--
Bruce Weaver bweaver@lakeheadu.ca http://sites.google.com/a/lakeheadu.ca/bweaver/ "When all else fails, RTFM." PLEASE NOTE THE FOLLOWING: 1. My Hotmail account is not monitored regularly. To send me an e-mail, please use the address shown above. 2. The SPSSX Discussion forum on Nabble is no longer linked to the SPSSX-L listserv administered by UGA (https://listserv.uga.edu/). |
Re: delete duplicate brand names in the concatenated variable
|
|
In reply to this post by David Marso
Hi David:
I am having a problem while concatenating the variables. I have 5 variables (attached the sav file named data.sav) when I combine them the last variable data is not displayed in the final concatenated variable. Hence I have changed the order (attached the sav file named data1.sav)- and when I combined them, the concatenated variable has all the data. Could you please check the code and let me know where I am going wrong (the below code was earlier suggested by you). Here is the SPSS code which I am using to merge variables DEFINE MRMAC (START = !CHAREND("/") / END = !CHAREND("/") / X = !TOKENS(1) /nbval=!TOKENS(1)). string !X(a2500). do repeat var = !START to !END. IF INDEX(!X,CONCAT(valuelabels(var),';')) EQ 0 and char.length(valuelabels(var)) gt 0 !X = CONCAT(!X,valuelabels(var),";"). end repeat. COMPUTE !X = RTRIM(!X,";"). !ENDDEFINE. MRMAC START = AGE / END = SOCLAS / X = TEST. EXECUTE. MRMAC START = SOCLAS / END = LOCAT/ X = TEST. EXECUTE. Data.sav Data1.sav |
Re: delete duplicate brand names in the concatenated variable
|
Administrator
|
Please don't expect me to exert extra labor to download your files!!!
I did try one and it won't open. System believes it to be an htm file. Paste some small sample data between data list/begin data/end data along with a listing. If you can't replicate with that then there's something fishy in your actual data. As a general rule, don't expect anyone to do extra work when you could make it self contained in a post. ---
Please reply to the list and not to my personal email.
Those desiring my consulting or training services please feel free to email me. --- "Nolite dare sanctum canibus neque mittatis margaritas vestras ante porcos ne forte conculcent eas pedibus suis." Cum es damnatorum possederunt porcos iens ut salire off sanguinum cliff in abyssum?" |
Re: delete duplicate brand names in the concatenated variable
|
|
In reply to this post by jagadishpchary
Hi David:
Here is the syntax DATA LIST LIST / AGE SEX JOBR LOCAT SOCLAS. BEGIN DATA. 1,2,1,1,2 5,2,3,2,1 3,2,2,2,2 5,2,4,2,2 5,1,3,2,2 END DATA. LIST. VALUE LABELS AGE 1 "18-24" 2 "25-34" 3 "35-44" 4 "45-54" 5 "55-64". VALUE LABELS SEX 1 "MALE" 2 "FEMALE". VALUE LABELS JOBR 1 "FULL TIME EDUCATION" 2 "PART TIME" 3 "RETIRED" 4 "NOT WORKING". VALUE LABELS LOCAT 1 "RURAL" 2 "URBAN". VALUE LABELS SOCLAS 1 "D" 2 "E". |
«
Return to SPSSX Discussion
|
1 view|%1 views
| Free forum by Nabble | Edit this page |