generate data with fixed range and known correlation

generate data with fixed range and known correlation

|
I seem to have misplaced old syntax for a tutorial simulation that
generated a set of data with say 1500 cases that had 2 variables
that ranged from say 1 to 5 and a given correlation, say .25.
Does anybody have one at hand? Art Kendall Social Research Consultants ===================== To manage your subscription to SPSSX-L, send a message to [hidden email] (not to SPSSX-L), with no body text except the command. To leave the list, send the command SIGNOFF SPSSX-L For a list of commands to manage subscriptions, send the command INFO REFCARD
Art Kendall
Social Research Consultants |
Automatic reply: generate data with fixed range and known correlation
|
|
Hello,
Thank you for your email. I will be on maternity leave beginning Monday January 17th, returning on Monday, January 16th 2012. In my absence, please contact Valerie Villela, Policy and Program Analyst at [hidden email] and via telephone at 905-851-8821 X241 or Dan Buchanan, Director, Financial Policy at [hidden email] or via telephone at 905-851-8821 X229. Thanks! Genevieve Odoom Policy and Program Analyst OANHSS Suite 700 - 7050 Weston Rd. Woodbridge, ON L4L 8G7 Tel: (905) 851-8821 x 241 Fax: (905) 851-0744 [hidden email] www.oanhss.org<https://mail.oanhss.org/ecp/Organize/www.oanhss.org> ===================== To manage your subscription to SPSSX-L, send a message to [hidden email] (not to SPSSX-L), with no body text except the command. To leave the list, send the command SIGNOFF SPSSX-L For a list of commands to manage subscriptions, send the command INFO REFCARD |
Re: generate data with fixed range and known correlation
|
|
In reply to this post by Art Kendall
Maybe this could be a starting point. I found it in my "Miscellaneous SPSS folder". I don't remember the author's name: *Input the desired correlation matrix and save it to a file. matrix data variables=v1 to v10 /contents=corr. begin data. 1 .662 1 .661 .697 1 .641 .730 .703 1 .131 -.112 .033 .040 1 .253 .031 .185 .149 .641 1 .332 .133 .197 .132 .574 .630 1 .381 .304 .304 .382 .312 .509 .583 1 .413 .313 .276 .382 .254 .491 .491 .731 1 .520 .485 .450 .466 .034 .117 .294 .595 .534 1 end data. save outfile='C:\temp\corrmat.sav' /keep=v1 to v10. *Generate raw data. Change #i from 100 to your desired N. *Change x(10) and #j from 10 to the size of your correlation matrix, if different. new file. input program. loop #i=1 to 100. vector x(10). loop #j=1 to 10. compute x(#j)=rv.normal(0,1). end loop. end case. end loop. end file. end input program. execute. *Use the FACTOR procedure to generate principal components, which *will be uncorrelated and have mean 0 and standard deviation 1 for each *variable. Change "x10" to reflect a different number of variables if *necessary, and if doing this then also change the number of factors *(components) to generate and save. factor var=x1 to x10 /criteria=factors(10) /save=reg(all z). *Use the MATRIX procedure to transform the uncorrelated variables to *a set of correlated variables, and save these to a new file. These variables *will be named COL1 to COL10 (or whatever is the chosen number of *variables). matrix. get z /var=z1 to z10. get r /file='C:\temp\corrmat.sav'. compute out=z*chol(r). save out /outfile='C:\temp\generated_data.sav'. end matrix. *Get the generated data and test correlations. get file='C:\temp\generated_data.sav'. *Rename variables if desired. Replace "var1 to var10" with appropriate *variable names. rename variables (col1 to col10=var1 to var10). *Test correlations. correlations var1 to var10. HTH, Marta El 14/01/2011 17:49, Art Kendall escribió: I seem to have misplaced old syntax for a tutorial simulation that generated a set of data with say 1500 cases that had 2 variables that ranged from say 1 to 5 and a given correlation, say .25. -- For miscellaneous SPSS related statistical stuff, visit: http://gjyp.nl/marta/ |
|
|
In reply to this post by Art Kendall
Art,
The code below generates data that approximate a Pearson correlation of r=.25. Note that the variables X and Y are transformed to your specifications. That is, the mininum and maximum values for both variables are 1 and 5, respectively. The larger the sample size, the closer the simulated data will yield a sample Pearson correlation coefficient of r=.25. So if you change 1,500 to 100,000, for instance, the sample Pearson correlation coefficient should be much closer to r=.25. HTH. Ryan -- *Generate data. set seed 98765432. new file. inp pro. loop ID= 1 to 1500. comp correlation=.25. comp X = rv.normal(0,1). comp rawY = rv.normal(0,1). comp Y=X * correlation + RawY * (1 - correlation**2)**.5. end case. end loop. end file. end inp pro. exe. *Obtain minimum and maximum values of X and Y. AGGREGATE /OUTFILE=* MODE=ADDVARIABLES /X_max=MAX(X) /X_min=MIN(X) /Y_max=MAX(Y) /Y_min=MIN(Y). *Normalize data such that X and Y values range from 1 to 5. comp X = 1 + ((X - X_min) * (5 -1)) / (X_max - X_min). comp Y = 1 + ((Y - Y_min) * (5 -1)) / (Y_max - Y_min). execute. DELETE VARIABLES ID correlation RawY X_max X_min Y_max Y_min. *Compute r. CORRELATIONS /VARIABLES=X Y /PRINT=TWOTAIL NOSIG. On Fri, Jan 14, 2011 at 11:49 AM, Art Kendall <[hidden email]> wrote: > I seem to have misplaced old syntax for a tutorial simulation that generated > a set of data with say 1500 cases that had 2 variables that ranged from say > 1 to 5 and a given correlation, say .25. > > Does anybody have one at hand? > > Art Kendall > Social Research Consultants > > > ===================== To manage your subscription to SPSSX-L, send a message > to [hidden email] (not to SPSSX-L), with no body text except the > command. To leave the list, send the command SIGNOFF SPSSX-L For a list of > commands to manage subscriptions, send the command INFO REFCARD ===================== To manage your subscription to SPSSX-L, send a message to [hidden email] (not to SPSSX-L), with no body text except the command. To leave the list, send the command SIGNOFF SPSSX-L For a list of commands to manage subscriptions, send the command INFO REFCARD |
Re: generate data with fixed range and known correlation
|
|
Thank you.
For others on the list you can try different seeds until you get a "sample" with the correlation you want and then scatterplot the x and y. For developing intuitive feel for correlations see this link. http://cnx.org/content/m11212/latest/ Art Kendall Social Research Consultants On 1/15/2011 6:00 PM, R B wrote: > Art, > > The code below generates data that approximate a Pearson correlation > of r=.25. Note that the variables X and Y are transformed to your > specifications. That is, the mininum and maximum values for both > variables are 1 and 5, respectively. The larger the sample size, the > closer the simulated data will yield a sample Pearson correlation > coefficient of r=.25. So if you change 1,500 to 100,000, for instance, > the sample Pearson correlation coefficient should be much closer to > r=.25. > > HTH. > > Ryan > -- > > *Generate data. > set seed 98765432. > > new file. > inp pro. > > loop ID= 1 to 1500. > comp correlation=.25. > comp X = rv.normal(0,1). > comp rawY = rv.normal(0,1). > > comp Y=X * correlation + RawY * (1 - correlation**2)**.5. > > end case. > end loop. > > end file. > end inp pro. > > exe. > > *Obtain minimum and maximum values of X and Y. > AGGREGATE > /OUTFILE=* MODE=ADDVARIABLES > /X_max=MAX(X) > /X_min=MIN(X) > /Y_max=MAX(Y) > /Y_min=MIN(Y). > > *Normalize data such that X and Y values range from 1 to 5. > comp X = 1 + ((X - X_min) * (5 -1)) / (X_max - X_min). > comp Y = 1 + ((Y - Y_min) * (5 -1)) / (Y_max - Y_min). > execute. > > DELETE VARIABLES ID correlation RawY X_max X_min Y_max Y_min. > > *Compute r. > CORRELATIONS > /VARIABLES=X Y > /PRINT=TWOTAIL NOSIG. > > On Fri, Jan 14, 2011 at 11:49 AM, Art Kendall<[hidden email]> wrote: >> I seem to have misplaced old syntax for a tutorial simulation that generated >> a set of data with say 1500 cases that had 2 variables that ranged from say >> 1 to 5 and a given correlation, say .25. >> >> Does anybody have one at hand? >> >> Art Kendall >> Social Research Consultants >> >> >> ===================== To manage your subscription to SPSSX-L, send a message >> to [hidden email] (not to SPSSX-L), with no body text except the >> command. To leave the list, send the command SIGNOFF SPSSX-L For a list of >> commands to manage subscriptions, send the command INFO REFCARD > ===================== > To manage your subscription to SPSSX-L, send a message to > [hidden email] (not to SPSSX-L), with no body text except the > command. To leave the list, send the command > SIGNOFF SPSSX-L > For a list of commands to manage subscriptions, send the command > INFO REFCARD > ===================== To manage your subscription to SPSSX-L, send a message to [hidden email] (not to SPSSX-L), with no body text except the command. To leave the list, send the command SIGNOFF SPSSX-L For a list of commands to manage subscriptions, send the command INFO REFCARD
Art Kendall
Social Research Consultants |
|
|
Agreed. Setting different seed values for the random number generator
will result in samples that produce different estimates. I think it's fairly common to want to simulate multiple times when conducting a simulation study. It is probably worth mentioning that one could simulate x number of samples by looping the simulation code I provided previously. For those interested, take a look below at how I build upon the previous code to generate 10 samples of N=1500. Ryan -- *Generate data. set seed 98765432. new file. inp pro. comp iteration=-99. comp ID = -99. comp X = -99. comp rawY = -99. leave iteration to rawY. loop iteration = 1 to 10. loop ID= 1 to 1500. comp correlation=.25. comp X = rv.normal(0,1). comp rawY = rv.normal(0,1). comp Y=X * correlation + RawY * (1 - correlation**2)**.5. end case. end loop. end loop. end file. end inp pro. exe. On Sun, Jan 16, 2011 at 9:08 AM, Art Kendall <[hidden email]> wrote: > Thank you. > > For others on the list you can try different seeds until you get a "sample" > with the correlation you want and then scatterplot the x and y. > > For developing intuitive feel for correlations see this link. > http://cnx.org/content/m11212/latest/ > > Art Kendall > Social Research Consultants > > On 1/15/2011 6:00 PM, R B wrote: >> >> Art, >> >> The code below generates data that approximate a Pearson correlation >> of r=.25. Note that the variables X and Y are transformed to your >> specifications. That is, the mininum and maximum values for both >> variables are 1 and 5, respectively. The larger the sample size, the >> closer the simulated data will yield a sample Pearson correlation >> coefficient of r=.25. So if you change 1,500 to 100,000, for instance, >> the sample Pearson correlation coefficient should be much closer to >> r=.25. >> >> HTH. >> >> Ryan >> -- >> >> *Generate data. >> set seed 98765432. >> >> new file. >> inp pro. >> >> loop ID= 1 to 1500. >> comp correlation=.25. >> comp X = rv.normal(0,1). >> comp rawY = rv.normal(0,1). >> >> comp Y=X * correlation + RawY * (1 - correlation**2)**.5. >> >> end case. >> end loop. >> >> end file. >> end inp pro. >> >> exe. >> >> *Obtain minimum and maximum values of X and Y. >> AGGREGATE >> /OUTFILE=* MODE=ADDVARIABLES >> /X_max=MAX(X) >> /X_min=MIN(X) >> /Y_max=MAX(Y) >> /Y_min=MIN(Y). >> >> *Normalize data such that X and Y values range from 1 to 5. >> comp X = 1 + ((X - X_min) * (5 -1)) / (X_max - X_min). >> comp Y = 1 + ((Y - Y_min) * (5 -1)) / (Y_max - Y_min). >> execute. >> >> DELETE VARIABLES ID correlation RawY X_max X_min Y_max Y_min. >> >> *Compute r. >> CORRELATIONS >> /VARIABLES=X Y >> /PRINT=TWOTAIL NOSIG. >> >> On Fri, Jan 14, 2011 at 11:49 AM, Art Kendall<[hidden email]> wrote: >>> >>> I seem to have misplaced old syntax for a tutorial simulation that >>> generated >>> a set of data with say 1500 cases that had 2 variables that ranged from >>> say >>> 1 to 5 and a given correlation, say .25. >>> >>> Does anybody have one at hand? >>> >>> Art Kendall >>> Social Research Consultants >>> >>> >>> ===================== To manage your subscription to SPSSX-L, send a >>> message >>> to [hidden email] (not to SPSSX-L), with no body text except >>> the >>> command. To leave the list, send the command SIGNOFF SPSSX-L For a list >>> of >>> commands to manage subscriptions, send the command INFO REFCARD >> >> ===================== >> To manage your subscription to SPSSX-L, send a message to >> [hidden email] (not to SPSSX-L), with no body text except the >> command. To leave the list, send the command >> SIGNOFF SPSSX-L >> For a list of commands to manage subscriptions, send the command >> INFO REFCARD >> > ===================== To manage your subscription to SPSSX-L, send a message to [hidden email] (not to SPSSX-L), with no body text except the command. To leave the list, send the command SIGNOFF SPSSX-L For a list of commands to manage subscriptions, send the command INFO REFCARD |
Re: generate data with fixed range and known correlation
|
|
If it were worth the time, a PYTHON enthusiast could show the seed at
the beginning of each run, suppress the output except the seed and correlation. Then use the seed to generate a set of data for the demo. That would be a demo of the variability of samples results from a given population r, and save keeping many data files. However, it only took about 5 or six tries to get a seed that generated an r of .253. Art On 1/16/2011 8:18 PM, R B wrote: > Agreed. Setting different seed values for the random number generator > will result in samples that produce different estimates. > > I think it's fairly common to want to simulate multiple times when > conducting a simulation study. It is probably worth mentioning that > one could simulate x number of samples by looping the simulation code > I provided previously. For those interested, take a look below at how > I build upon the previous code to generate 10 samples of N=1500. > > Ryan > > -- > > *Generate data. > set seed 98765432. > > new file. > inp pro. > > comp iteration=-99. > comp ID = -99. > comp X = -99. > comp rawY = -99. > > leave iteration to rawY. > > loop iteration = 1 to 10. > loop ID= 1 to 1500. > comp correlation=.25. > comp X = rv.normal(0,1). > comp rawY = rv.normal(0,1). > > comp Y=X * correlation + RawY * (1 - correlation**2)**.5. > > end case. > end loop. > end loop. > > end file. > > end inp pro. > > exe. > > On Sun, Jan 16, 2011 at 9:08 AM, Art Kendall<[hidden email]> wrote: >> Thank you. >> >> For others on the list you can try different seeds until you get a "sample" >> with the correlation you want and then scatterplot the x and y. >> >> For developing intuitive feel for correlations see this link. >> http://cnx.org/content/m11212/latest/ >> >> Art Kendall >> Social Research Consultants >> >> On 1/15/2011 6:00 PM, R B wrote: >>> Art, >>> >>> The code below generates data that approximate a Pearson correlation >>> of r=.25. Note that the variables X and Y are transformed to your >>> specifications. That is, the mininum and maximum values for both >>> variables are 1 and 5, respectively. The larger the sample size, the >>> closer the simulated data will yield a sample Pearson correlation >>> coefficient of r=.25. So if you change 1,500 to 100,000, for instance, >>> the sample Pearson correlation coefficient should be much closer to >>> r=.25. >>> >>> HTH. >>> >>> Ryan >>> -- >>> >>> *Generate data. >>> set seed 98765432. >>> >>> new file. >>> inp pro. >>> >>> loop ID= 1 to 1500. >>> comp correlation=.25. >>> comp X = rv.normal(0,1). >>> comp rawY = rv.normal(0,1). >>> >>> comp Y=X * correlation + RawY * (1 - correlation**2)**.5. >>> >>> end case. >>> end loop. >>> >>> end file. >>> end inp pro. >>> >>> exe. >>> >>> *Obtain minimum and maximum values of X and Y. >>> AGGREGATE >>> /OUTFILE=* MODE=ADDVARIABLES >>> /X_max=MAX(X) >>> /X_min=MIN(X) >>> /Y_max=MAX(Y) >>> /Y_min=MIN(Y). >>> >>> *Normalize data such that X and Y values range from 1 to 5. >>> comp X = 1 + ((X - X_min) * (5 -1)) / (X_max - X_min). >>> comp Y = 1 + ((Y - Y_min) * (5 -1)) / (Y_max - Y_min). >>> execute. >>> >>> DELETE VARIABLES ID correlation RawY X_max X_min Y_max Y_min. >>> >>> *Compute r. >>> CORRELATIONS >>> /VARIABLES=X Y >>> /PRINT=TWOTAIL NOSIG. >>> >>> On Fri, Jan 14, 2011 at 11:49 AM, Art Kendall<[hidden email]> wrote: >>>> I seem to have misplaced old syntax for a tutorial simulation that >>>> generated >>>> a set of data with say 1500 cases that had 2 variables that ranged from >>>> say >>>> 1 to 5 and a given correlation, say .25. >>>> >>>> Does anybody have one at hand? >>>> >>>> Art Kendall >>>> Social Research Consultants >>>> >>>> >>>> ===================== To manage your subscription to SPSSX-L, send a >>>> message >>>> to [hidden email] (not to SPSSX-L), with no body text except >>>> the >>>> command. To leave the list, send the command SIGNOFF SPSSX-L For a list >>>> of >>>> commands to manage subscriptions, send the command INFO REFCARD >>> ===================== >>> To manage your subscription to SPSSX-L, send a message to >>> [hidden email] (not to SPSSX-L), with no body text except the >>> command. To leave the list, send the command >>> SIGNOFF SPSSX-L >>> For a list of commands to manage subscriptions, send the command >>> INFO REFCARD >>> > ===================== > To manage your subscription to SPSSX-L, send a message to > [hidden email] (not to SPSSX-L), with no body text except the > command. To leave the list, send the command > SIGNOFF SPSSX-L > For a list of commands to manage subscriptions, send the command > INFO REFCARD > ===================== To manage your subscription to SPSSX-L, send a message to [hidden email] (not to SPSSX-L), with no body text except the command. To leave the list, send the command SIGNOFF SPSSX-L For a list of commands to manage subscriptions, send the command INFO REFCARD
Art Kendall
Social Research Consultants |
Re: generate data with fixed range and known correlation
|
Administrator
|
Here is a lean, mean, clean version which will generate rather precise values.
I will leave it to you to back transform the resulting variables to have a specified min/max. I believe Ryan's post does this. This is similar in spirit to Marta's solution but uses the Singular Value Transformation rather than FACTOR to produce uncorrelated variables from the simulated input vectors. MAJICK???... Nah, but is might seem that way (SVD has some rather remarkable properties!!!) -------- DEFINE BIV (N !TOKENS(1) / R !TOKENS(1) ). INPUT PROGRAM. LOOP #=1 to !N. COMPUTE X1=Normal(1). COMPUTE X2=Normal(1). END CASE. END LOOP. END FILE. END INPUT PROGRAM. DESC X1 X2 / SAVE. MATRIX. GET Z / FILE * / VARIABLES ZX1 ZX2. CALL SVD(T(Z)*Z/(NROW(Z)-1) ,V,D,U). SAVE (Z * T(V) *SQRT(D) *CHOL({1,!R; !R, 1})) /OUTFILE *. END MATRIX. CORR COL1 COL2 / STAT=DESC. !ENDDEFINE . BIV N=1000 R=.6 . BIV N=3000 R=.8 . BIV N=5000 R=.9 . BIV N=2059 R=.7254 .
Please reply to the list and not to my personal email.
Those desiring my consulting or training services please feel free to email me. --- "Nolite dare sanctum canibus neque mittatis margaritas vestras ante porcos ne forte conculcent eas pedibus suis." Cum es damnatorum possederunt porcos iens ut salire off sanguinum cliff in abyssum?" |
Re: generate data with fixed range and known correlation
|
|
In reply to this post by Art Kendall
This is a bit off-topic, but relevant I think, and
I need to do something similar for the next tranche of SPSS tutorials on my
site.
Many years ago when I was teaching survey analysis
and SPSS to previously non-numerate students, I used to do something similar to
demonstrate variation in means, chi-square etc. by using SEED and
SAMPLE. Taking the data from one of the British Social Attitudes surveys
and treating it as the population (N approx 3000) I got students to calculate a
percentage (% male) a mean (age last birthday) from that and then draw two
different sub-samples of 300 (using their birthdate yymmdd as the seed) of 300
and report them back to class. Given an average class size of 25
students this would yield up to 50 readings. These were then plotted on
the chalk-board (remember those?) to demonstrate sampling variation of the mean
and that would be approximately normal regardless of the original
distribution of values.
The same exercise also did crosstabs on sex (2) and
agegroup (4) by attitudes to abortion "Yes - No" to ". . . should be allowed if
the woman does not want the child." to obtain % Yes and
chi-square.
Yes, you guessed, there were never
sufficient plots to demonstrate the expected normal distribution, but the
students understood the general idea behind the term "sampling error of the
mean". Later I ran my own tests sampling up to 2000 from 3000 and
obtained more compliant results, but it was tedious doing this many
times.
Is there any simple way I can run a similar
exercise to obtain anything up to 500 or even 1000 different samples and retain
the results for plotting, or even plot them within the same job? Would
1000 be enough?
|
Re: generate data with fixed range and known correlation
|
Administrator
|
Hi John,
This should do what you want. You can clean up the GRAPH function a bit as I am using a stone age version of SPSS ;-( ---------------- I Borrowed Ryan's function. "+ COMPUTE y= x * !CORR + #RawY * (1 - !CORR**2)**.5. "... *Generate data. DEFINE SIMBIVN ( SEED !CHAREND ("/") / NSAMP !CHAREND ("/") / SAMPSIZ !CHAREND ("/") / CORR !CMDEND ). SET SEED !SEED. INPUT PROGRAM. LOOP sample= 1 TO !NSAMP. + LEAVE sample. + LOOP #=1 TO !SAMPSIZ. + COMPUTE x = rv.normal(0,1). + COMPUTE #rawY = rv.normal(0,1). + COMPUTE y= x * !CORR + #RawY * (1 - !CORR**2)**.5. + END CASE. + END LOOP. END LOOP. END FILE. END INPUT PROGRAM. SPLIT FILE BY sample. * Mileage may vary WRT the following line *. * It's an ODD old story how this one came to be ;-) *. SET RESULTS NONE ERRORS NONE. CORR x y / MATRIX OUT(*). SELECT IF rowtype_="CORR" AND varname_="Y". * Better turn ON results/errors and turn off split file ;-) *. SET RESULTS ON ERRORS ON. SPLIT FILE OFF. * You are on your own from here... i.e Bling it as you wish ;-) . DESCRIPTIVES VARIABLES=x /STATISTICS=MEAN STDDEV VARIANCE RANGE MIN MAX KURTOSIS SKEWNESS . GRAPH /HISTOGRAM(NORMAL)=x . !ENDDEFINE. SIMBIVN SEED 98765432 / NSAMP 1000 / SAMPSIZ 1000 / CORR .7 . SIMBIVN SEED 98765432 / NSAMP 1000 / SAMPSIZ 100 / CORR .7 .
Please reply to the list and not to my personal email.
Those desiring my consulting or training services please feel free to email me. --- "Nolite dare sanctum canibus neque mittatis margaritas vestras ante porcos ne forte conculcent eas pedibus suis." Cum es damnatorum possederunt porcos iens ut salire off sanguinum cliff in abyssum?" |
Re: generate data with fixed range and known correlation
|
Administrator
|
In reply to this post by John F Hall
Hi John,
This should do what you want. You can clean up the GRAPH function a bit as I am using a stone age version of SPSS ;-( ---------------- I Borrowed Ryan's function. "+ COMPUTE y= x * !CORR + #RawY * (1 - !CORR**2)**.5. "... *Generate data. DEFINE SIMBIVN ( SEED !CHAREND ("/") / NSAMP !CHAREND ("/") / SAMPSIZ !CHAREND ("/") / CORR !CMDEND ). SET SEED !SEED. INPUT PROGRAM. LOOP sample= 1 TO !NSAMP. + LEAVE sample. + LOOP #=1 TO !SAMPSIZ. + COMPUTE x = rv.normal(0,1). + COMPUTE #rawY = rv.normal(0,1). + COMPUTE y= x * !CORR + #RawY * (1 - !CORR**2)**.5. + END CASE. + END LOOP. END LOOP. END FILE. END INPUT PROGRAM. SPLIT FILE BY sample. * Mileage may vary WRT the following line *. * It's an ODD old story how this one came to be ;-) *. SET RESULTS NONE ERRORS NONE. CORR x y / MATRIX OUT(*). SELECT IF rowtype_="CORR" AND varname_="Y". * Better turn ON results/errors and turn off split file ;-) *. SET RESULTS ON ERRORS ON. SPLIT FILE OFF. * You are on your own from here... i.e Bling it as you wish ;-) . DESCRIPTIVES VARIABLES=x /STATISTICS=MEAN STDDEV VARIANCE RANGE MIN MAX KURTOSIS SKEWNESS . GRAPH /HISTOGRAM(NORMAL)=x . !ENDDEFINE. SIMBIVN SEED 98765432 / NSAMP 1000 / SAMPSIZ 1000 / CORR .7 . SIMBIVN SEED 98765432 / NSAMP 1000 / SAMPSIZ 100 / CORR .7 . On Tue, Jan 18, 2011 at 4:06 AM, John F Hall [via SPSSX Discussion] <[hidden email]> wrote: > This is a bit off-topic, but relevant I think, and I need to do something > similar for the next tranche of SPSS tutorials on my site. > > Many years ago when I was teaching survey analysis and SPSS to previously > non-numerate students, I used to do something similar to demonstrate > variation in means, chi-square etc. by using SEED and SAMPLE. Taking the > data from one of the British Social Attitudes surveys and treating it as the > population (N approx 3000) I got students to calculate a percentage (% male) > a mean (age last birthday) from that and then draw two different sub-samples > of 300 (using their birthdate yymmdd as the seed) of 300 and report them > back to class. Given an average class size of 25 students this would yield > up to 50 readings. These were then plotted on the chalk-board (remember > those?) to demonstrate sampling variation of the mean and that would > be approximately normal regardless of the original distribution of values. > > The same exercise also did crosstabs on sex (2) and agegroup (4) by > attitudes to abortion "Yes - No" to ". . . should be allowed if the woman > does not want the child." to obtain % Yes and chi-square. > > Yes, you guessed, there were never sufficient plots to demonstrate the > expected normal distribution, but the students understood the general idea > behind the term "sampling error of the mean". Later I ran my own tests > sampling up to 2000 from 3000 and obtained more compliant results, but it > was tedious doing this many times. > > Is there any simple way I can run a similar exercise to obtain anything up > to 500 or even 1000 different samples and retain the results for plotting, > or even plot them within the same job? Would 1000 be enough? > > John Hall > [hidden email] > http://surveyresearch.weebly.com > > > > ----- Original Message ----- > From: [hidden email] > To: [hidden email] > Sent: Monday, January 17, 2011 2:13 PM > Subject: Re: generate data with fixed range and known correlation > If it were worth the time, a PYTHON enthusiast could show the seed at > the beginning of each run, suppress the output except the seed and > correlation. Then use the seed to generate a set of data for the > demo. That would be a demo of the variability of samples results from a > given population r, and save keeping many data files. > > However, it only took about 5 or six tries to get a seed that generated > an r of .253. > > Art > > On 1/16/2011 8:18 PM, R B wrote: >> Agreed. Setting different seed values for the random number generator >> will result in samples that produce different estimates. >> >> I think it's fairly common to want to simulate multiple times when >> conducting a simulation study. It is probably worth mentioning that >> one could simulate x number of samples by looping the simulation code >> I provided previously. For those interested, take a look below at how >> I build upon the previous code to generate 10 samples of N=1500. >> >> Ryan >> >> -- >> >> *Generate data. >> set seed 98765432. >> >> new file. >> inp pro. >> >> comp iteration=-99. >> comp ID = -99. >> comp X = -99. >> comp rawY = -99. >> >> leave iteration to rawY. >> >> loop iteration = 1 to 10. >> loop ID= 1 to 1500. >> comp correlation=.25. >> comp X = rv.normal(0,1). >> comp rawY = rv.normal(0,1). >> >> comp Y=X * correlation + RawY * (1 - correlation**2)**.5. >> >> end case. >> end loop. >> end loop. >> >> end file. >> >> end inp pro. >> >> exe. >> >> On Sun, Jan 16, 2011 at 9:08 AM, Art Kendall<[hidden email]> wrote: >>> Thank you. >>> >>> For others on the list you can try different seeds until you get a >>> "sample" >>> with the correlation you want and then scatterplot the x and y. >>> >>> For developing intuitive feel for correlations see this link. >>> http://cnx.org/content/m11212/latest/ >>> >>> Art Kendall >>> Social Research Consultants >>> >>> On 1/15/2011 6:00 PM, R B wrote: >>>> Art, >>>> >>>> The code below generates data that approximate a Pearson correlation >>>> of r=.25. Note that the variables X and Y are transformed to your >>>> specifications. That is, the mininum and maximum values for both >>>> variables are 1 and 5, respectively. The larger the sample size, the >>>> closer the simulated data will yield a sample Pearson correlation >>>> coefficient of r=.25. So if you change 1,500 to 100,000, for instance, >>>> the sample Pearson correlation coefficient should be much closer to >>>> r=.25. >>>> >>>> HTH. >>>> >>>> Ryan >>>> -- >>>> >>>> *Generate data. >>>> set seed 98765432. >>>> >>>> new file. >>>> inp pro. >>>> >>>> loop ID= 1 to 1500. >>>> comp correlation=.25. >>>> comp X = rv.normal(0,1). >>>> comp rawY = rv.normal(0,1). >>>> >>>> comp Y=X * correlation + RawY * (1 - correlation**2)**.5. >>>> >>>> end case. >>>> end loop. >>>> >>>> end file. >>>> end inp pro. >>>> >>>> exe. >>>> >>>> *Obtain minimum and maximum values of X and Y. >>>> AGGREGATE >>>> /OUTFILE=* MODE=ADDVARIABLES >>>> /X_max=MAX(X) >>>> /X_min=MIN(X) >>>> /Y_max=MAX(Y) >>>> /Y_min=MIN(Y). >>>> >>>> *Normalize data such that X and Y values range from 1 to 5. >>>> comp X = 1 + ((X - X_min) * (5 -1)) / (X_max - X_min). >>>> comp Y = 1 + ((Y - Y_min) * (5 -1)) / (Y_max - Y_min). >>>> execute. >>>> >>>> DELETE VARIABLES ID correlation RawY X_max X_min Y_max Y_min. >>>> >>>> *Compute r. >>>> CORRELATIONS >>>> /VARIABLES=X Y >>>> /PRINT=TWOTAIL NOSIG. >>>> >>>> On Fri, Jan 14, 2011 at 11:49 AM, Art Kendall<[hidden email]> wrote: >>>>> I seem to have misplaced old syntax for a tutorial simulation that >>>>> generated >>>>> a set of data with say 1500 cases that had 2 variables that ranged from >>>>> say >>>>> 1 to 5 and a given correlation, say .25. >>>>> >>>>> Does anybody have one at hand? >>>>> >>>>> Art Kendall >>>>> Social Research Consultants >>>>> >>>>> >>>>> ===================== To manage your subscription to SPSSX-L, send a >>>>> message >>>>> to [hidden email] (not to SPSSX-L), with no body text except >>>>> the >>>>> command. To leave the list, send the command SIGNOFF SPSSX-L For a list >>>>> of >>>>> commands to manage subscriptions, send the command INFO REFCARD >>>> ===================== >>>> To manage your subscription to SPSSX-L, send a message to >>>> [hidden email] (not to SPSSX-L), with no body text except the >>>> command. To leave the list, send the command >>>> SIGNOFF SPSSX-L >>>> For a list of commands to manage subscriptions, send the command >>>> INFO REFCARD >>>> >> ===================== >> To manage your subscription to SPSSX-L, send a message to >> [hidden email] (not to SPSSX-L), with no body text except the >> command. To leave the list, send the command >> SIGNOFF SPSSX-L >> For a list of commands to manage subscriptions, send the command >> INFO REFCARD >> > ===================== > To manage your subscription to SPSSX-L, send a message to > [hidden email] (not to SPSSX-L), with no body text except the > command. To leave the list, send the command > SIGNOFF SPSSX-L > For a list of commands to manage subscriptions, send the command > INFO REFCARD > > > ________________________________ > View message @ > http://spssx-discussion.1045642.n5.nabble.com/generate-data-with-fixed-range-and-known-correlation-tp3341581p3345849.html > To unsubscribe from generate data with fixed range and known correlation, > click here.
Please reply to the list and not to my personal email.
Those desiring my consulting or training services please feel free to email me. --- "Nolite dare sanctum canibus neque mittatis margaritas vestras ante porcos ne forte conculcent eas pedibus suis." Cum es damnatorum possederunt porcos iens ut salire off sanguinum cliff in abyssum?" |
Re: generate data with fixed range and known correlation
|
|
In reply to this post by David Marso
David
. . . and you call that simple!
Many thanks: way over my head for today, but I'll
try to work out what all the syntax means and have a shot. I ran a couple
of tests on the 1986 British Social Attitudes data and confirmed that the
samples are different each time without having to reset the seed, so the
students got different results unless, as happened more than once, two or
more students had the same date of birth: that's why we used yymmdd instead of
mmdd.
The syntax I used was:
cro sex agegroup by v2020 /cel cou
row /sta chi .
set seed 401207 .
temp .
sample 200 from 1266 . cro sex agegroup by v2020 /cel cou row /sta chi . temp .
sample 200 from 1266 . cro sex agegroup by v2020 /cel cou row /sta chi . What I'm really after (with minimal effort on my
part) is a data set consisting of extracts from the crosstabs cells (eg %
Definitely not) and the chi-square value. Another time it might be % "Very
happy" or mean satisfaction (0 - 10) with various life domains or life as a
whole. These examples can then be used to introduce users to inferential
rather than descriptive statistics.
PS The variable I used in class wasn't
abortion (Yes/No) it was whether people should be allowed to go on marches and
demonstrations (Definitely/ Probably/ Probably not/ Definitely not).
Lovely gradient with agegroups on "Definitely not". Must get the 2008 data
and see if anything has changed in the last 22 years.
|
Re: generate data with fixed range and known correlation
|
Administrator
|
In reply to this post by David Marso
Please reply to the list and not to my personal email.
Those desiring my consulting or training services please feel free to email me. --- "Nolite dare sanctum canibus neque mittatis margaritas vestras ante porcos ne forte conculcent eas pedibus suis." Cum es damnatorum possederunt porcos iens ut salire off sanguinum cliff in abyssum?" |
Re: generate data with fixed range and known correlation
|
Administrator
|
In reply to this post by John F Hall
"temp .
sample 200 from 1266 . cro sex agegroup by v2020 /cel cou row /sta chi . temp . sample 200 from 1266 . cro sex agegroup by v2020 /cel cou row /sta ch" .... YOU REALLY ****DON'T**** want to do it that way!!!!! You really don't want to bother using XTABS to create the Chi Squares. It is entirely TRIVIAL to compute it using a few aggregates. ...". . . and you call that simple! "..... Compared to what I do for my consulting clients it is pretty simple ;-) *************************************************** *** COMMON TO BOTH sets of code (OLD SPSS and NEW SPSS). GET FILE='C:\Program Files\SPSS\1991 U.S. General Social Survey.sav'. COMPUTE ID=$CASENUM. LOOP S=1 to 1000. + COMPUTE R=UNIFORM(1). * Randomly extract approximately 10% of our cases for each of 1000 samples!!!. + DO IF R < .1. + XSAVE OUTFILE "C:\TEMP\BIV.SAV" / KEEP S ID sex happy. + END IF. END LOOP. EXE. GET FILE "C:\TEMP\BIV.SAV". ***********************************************************. *OLD SPSS*. AGGREGATE OUTFILE * / BREAK S sex happy / NhapSex=N. MATCH FILES / FILE * / TABLE="C:\TEMP\SexHappy.sav"/BY S SEX Happy . AGGREGATE OUTFILE "C:\TEMP\SEX.sav" / BREAK S SEX / Nsex=SUM(NhapSex). MATCH FILES / FILE * / TABLE="C:\TEMP\SEX.sav" /BY S SEX . SORT CASES BY S happy. AGGREGATE OUTFILE "C:\TEMP\Happy.sav" / BREAK S happy/ Nhappy=SUM(NhapSex). MATCH FILES / FILE * / TABLE="C:\TEMP\Happy.sav"/BY S Happy . AGGREGATE OUTFILE "C:\TEMP\N.sav" / BREAK S / NTot=SUM(NhapSex). MATCH FILES / FILE * / TABLE="C:\TEMP\N.sav"/BY S . COMPUTE EXP=NSEX*NHappy/NTot. COMPUTE Chi=(NHapSex-EXP)**2 / EXP. AGGREGATE OUTFILE * / BREAK S / ChiSq=SUM(Chi). *NEW SPSS /UNTESTED/*. AGGREGATE OUTFILE * / BREAK S sex happy / NhapSex=N. AGGREGATE OUTFILE "C:\TEMP\SEX.sav" / MODE=ADDVARIABLES / BREAK S SEX / Nsex=SUM(NhapSex). AGGREGATE OUTFILE "C:\TEMP\Happy.sav" / MODE=ADDVARIABLES / BREAK S happy/ Nhappy=SUM(NhapSex). AGGREGATE OUTFILE "C:\TEMP\N.sav" / MODE=ADDVARIABLES / BREAK S / NTot=SUM(NhapSex). COMPUTE EXP=NSEX*NHappy/NTot. COMPUTE Chi=(NHapSex-EXP)**2 / EXP. AGGREGATE OUTFILE * / BREAK S / ChiSq=SUM(Chi). You now have an active file of 1000 chi squares from 10% random samples of the data file. HTH, David 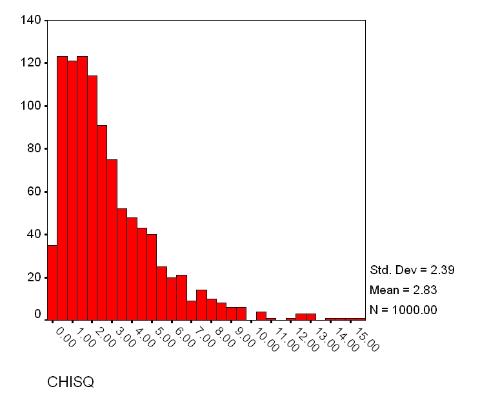
Please reply to the list and not to my personal email.
Those desiring my consulting or training services please feel free to email me. --- "Nolite dare sanctum canibus neque mittatis margaritas vestras ante porcos ne forte conculcent eas pedibus suis." Cum es damnatorum possederunt porcos iens ut salire off sanguinum cliff in abyssum?" |
Re: generate data with fixed range and known correlation
|
Administrator
|
David, here's an alternative method for the back end of your example using "NEW SPSS" methods--i.e., OMS and the ability to have more than one dataset open at a time. GET FILE "C:\TEMP\BIV.SAV". dataset name samples. * Use OMS to write chi-square tests to another dataset. DATASET DECLARE chisq. OMS /SELECT TABLES /IF COMMANDS=['Crosstabs'] SUBTYPES=['Chi Square Tests'] /DESTINATION FORMAT=SAV NUMBERED=TableNumber_ OUTFILE='chisq'. * Use OMS to suppress output to viewer. OMS /SELECT TABLES /IF COMMANDS=['Crosstabs'] SUBTYPES=['Case Processing Summary' ' Crosstabulation' 'Chi Square Tests'] /DESTINATION VIEWER=NO. * Compute the chi-square statistics. dataset activate samples. crosstabs sex by happy by S / stat = chisqr . OMSEND. * Activate the data set containing the chi-square statistics. dataset activate chisq window = front. * Select the Pearson Chi-Square row, and plot. temporary. select if (var2 EQ "Pearson Chi-Square"). graph histogram value.
--
Bruce Weaver bweaver@lakeheadu.ca http://sites.google.com/a/lakeheadu.ca/bweaver/ "When all else fails, RTFM." PLEASE NOTE THE FOLLOWING: 1. My Hotmail account is not monitored regularly. To send me an e-mail, please use the address shown above. 2. The SPSSX Discussion forum on Nabble is no longer linked to the SPSSX-L listserv administered by UGA (https://listserv.uga.edu/). |
Re: generate data with fixed range and known correlation
|
|
In reply to this post by David Marso
Difference is my students understood it: logic,
syntax, results and a bit of inferential statistics.
|
«
Return to SPSSX Discussion
|
1 view|%1 views
| Free forum by Nabble | Edit this page |