inter-rater reliability with multiple raters

inter-rater reliability with multiple raters

|
Hi everyone! I need help with a research assignment. I'm new to IBM SPSS statistics, and actually statistics in general, so i'm pretty overwhelmed.
My coworkers and I created a new observation scale to improve the concise transfer of information between nurses and other psychiatric staff. This scale is designed to facilitate clinical care and outcomes related research. Nurses and other staff members on our particular inpatient unit will use standard clinical observations to rate patient behaviors in eight categories (abnormal motor activity, activities of daily living, bizarre/disorganized behavior, medication adherence, aggression, observation status, participation in assessment, and quality of social interactions). Each category will be given a score 0-4, and those ratings will be summed to create a a total rating. At least two nurses will rate each patient during each shift, morning and evening (so one patient should theoretically have at least four ratings per day). My assignment is to examine the reliability and validity of this new scale, and determine its utility for transfer of information. Right now I'm trying to figure out how to examine inter-rater reliability. IBM SPSS doesn't have a program to calculate Fleiss kappa (that I know of) and I'm not sure if that's what I should be calculating anyway...I'm confused because there are multiple raters, multiple patients, and multiple dates/times/shifts. The raters differ from day to day even on the same patient's chart, so there is a real lack of consistency in the data. Also sometimes only one rating is done on a shift...sometimes the nurses skip a shift of rating altogether. Also there are different lengths of stay for each patient, so the amount of data collected for each one differs dramatically. I've attached a screenshot of part of our unidentified data. Can anyone please help me figure out how to determine inter-rater reliability? (Or if anyone has any insight into how to determine validity, that'd be great too!) Thanks so much! 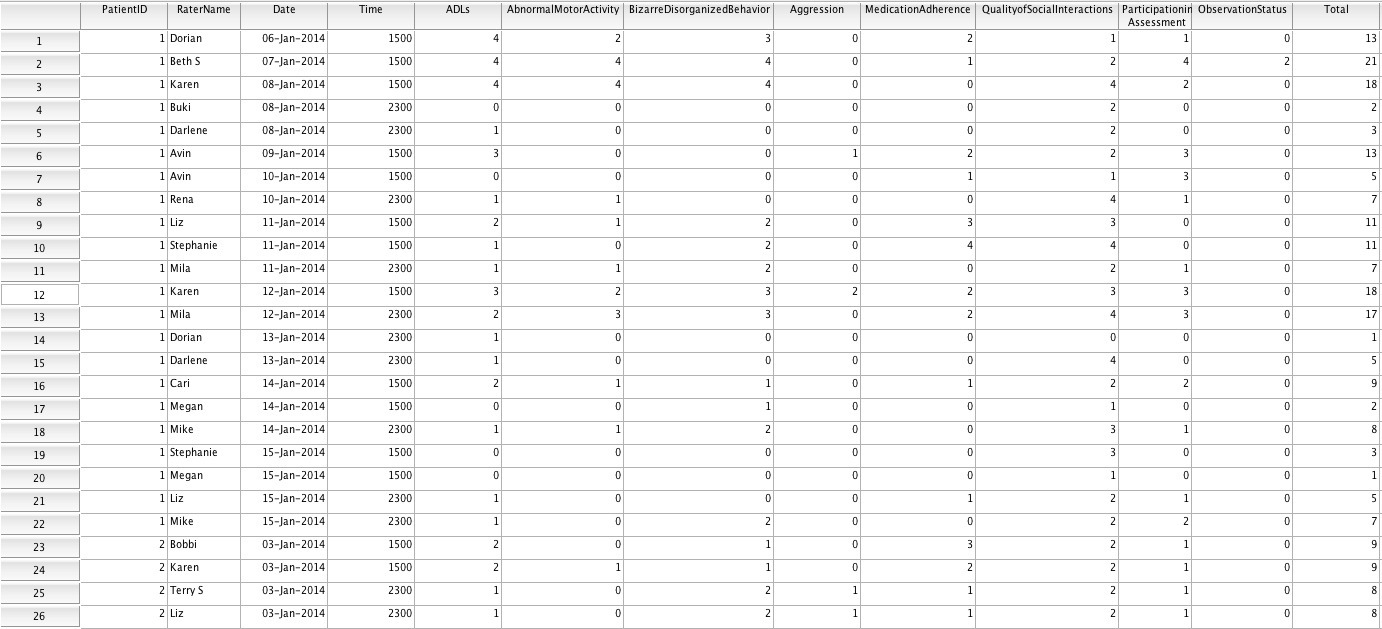
|
|
|
Check these out may help: ftp://ftp.boulder.ibm.com/software/analytics/spss/support/Stats/Docs/Statistics/Macros/Iccsf.htm Hi everyone! I need help with a research assignment. I'm new to IBM SPSS statistics, and actually statistics in general, so i'm pretty overwhelmed. Nurses and other staff members on our particular inpatient unit will use standard clinical observations to rate patient behaviors in eight categories ( 1. abnormal motor activity, 2. activities of daily living, 3. bizarre/disorganized behavior, 4. medication adherence, 5. aggression, 6. observation status, 7. participation in assessment, and 8. quality of social interactions). Each category will be given a score 0-4, and those ratings will be summed to create a a total rating. At least two nurses will rate each patient during each shift, morning and evening (so one patient should theoretically have at least four ratings per day). |
Re: inter-rater reliability with multiple raters
|
|
In reply to this post by redeyedfrog
This is not really about using SPSS, but about analyzing data. You can
continue this by email if you want, especially for the clinical aspects. My own work experience was psychiatric research (though "outpatient" for the most part). Whatever you do that fits some good model is going to select a small part of the data that exists. For instance, you *might* look at the first pair of ratings for each patient (selecting where a pair exists), and nothing else, in order to produce a simple, fairly ordinary ICC. That is mainly useful if you have at least a few dozen patients. There is, of course, a difference in what you should expect if the basis of the two raters is not based on "observation that they share." That is, in my experience with psychiatric data, most ratings came from interviews, or from viewing tapes of interactions. Two raters independently interacting during a shift will have different experiences. Whatever you do, you should start by documenting how much data you actually have: How many patients? How many raters? How many ratings? How many periods with at least a pair of ratings? And then: Who are you trying to impress with the data? What comes next? Is this regarded as a pilot experience for something else? Would you consider it as a tool for training the raters to achieve better consistency, or for discussing *differences* so that you might review and revise the anchors that describe the behaviors? (Have you looked at the manuals for IMPS and BPRS? Did you start with them?) Just to see how the variation exists, I would do a set of ANOVAs that tests PatientID, RaterID, and something to do with duration of stay. I would test those, also, for "first week only" and "later weeks". Assuming that there are new admissions, psychiatric patients show most pathology in the first week. It might be that the useful variation only exists within the first week, and that you can ignore the data after that with very little loss of generality... or, with a special point to be made about ratings differences that exist later on during the stay. As to "validity" -- the early-admission ratings should correlate with diagnosis, assuming that there is some wide variation in diagnosis... which is not entirely likely if these are all from one unit with the same basic Dx. Anything to do with outcome might be a little bit interesting, but you cannot separate cause from effect, since you have to assume that the doctors and nurses do pay *some* attention to the experience and opinions of each other. -- Rich Ulrich > Date: Fri, 13 Jun 2014 19:54:56 -0700 > From: [hidden email] > Subject: inter-rater reliability with multiple raters > To: [hidden email] > > Hi everyone! I need help with a research assignment. I'm new to IBM SPSS > statistics, and actually statistics in general, so i'm pretty overwhelmed. > > My coworkers and I created a new observation scale to improve the concise > transfer of information between nurses and other psychiatric staff. This > scale is designed to facilitate clinical care and outcomes related research. > Nurses and other staff members on our particular inpatient unit will use > standard clinical observations to rate patient behaviors in eight categories > (abnormal motor activity, activities of daily living, bizarre/disorganized > behavior, medication adherence, aggression, observation status, > participation in assessment, and quality of social interactions). Each > category will be given a score 0-4, and those ratings will be summed to > create a a total rating. At least two nurses will rate each patient during > each shift, morning and evening (so one patient should theoretically have at > least four ratings per day). > > My assignment is to examine the reliability and validity of this new scale, > and determine its utility for transfer of information. > > Right now I'm trying to figure out how to examine inter-rater reliability. > IBM SPSS doesn't have a program to calculate Fleiss kappa (that I know of) > and I'm not sure if that's what I should be calculating anyway...I'm > confused because there are multiple raters, multiple patients, and multiple > dates/times/shifts. The raters differ from day to day even on the same > patient's chart, so there is a real lack of consistency in the data. Also > sometimes only one rating is done on a shift...sometimes the nurses skip a > shift of rating altogether. Also there are different lengths of stay for > each patient, so the amount of data collected for each one differs > dramatically. > > I've attached a screenshot of part of our unidentified data. Can anyone > please help me figure out how to determine inter-rater reliability? (Or if > anyone has any insight into how to determine validity, that'd be great too!) > > Thanks so much! > > <http://spssx-discussion.1045642.n5.nabble.com/file/n5726465/deidentified_data.jpg> > > |
Re: inter-rater reliability with multiple raters
|
|
In reply to this post by redeyedfrog
There was a discussion of this topic in an earlier thread: http://spssx-discussion.1045642.n5.nabble.com/Fleiss-Kappa-Inter-rater-reliability-questions-td5717299.html
You may also want to look into G Theory as an option, as it allows you to look at different combinations of sources of variance in you outcomes (e.g., raters, occasions). For example, see http://journals.cambridge.org/action/displayAbstract?fromPage=online&aid=85843 (sorry, but could not find a link to a free version of the article). |
Re: inter-rater reliability with multiple raters
|
Administrator
|
Here's a free version: http://www.researchgate.net/publication/11770441_G_theory_and_the_reliability_of_psychophysiological_measures_a_tutorial/file/9fcfd50dd7cbc6d6bf.pdf
--
Bruce Weaver bweaver@lakeheadu.ca http://sites.google.com/a/lakeheadu.ca/bweaver/ "When all else fails, RTFM." PLEASE NOTE THE FOLLOWING: 1. My Hotmail account is not monitored regularly. To send me an e-mail, please use the address shown above. 2. The SPSSX Discussion forum on Nabble is no longer linked to the SPSSX-L listserv administered by UGA (https://listserv.uga.edu/). |
Re: inter-rater reliability with multiple raters
|
|
In reply to this post by MaxJasper
"IBM SPSS doesn't have a program
to calculate Fleiss
kappa (that I know of) "
See the STATS FLEISS KAPPA custom dialog. It requires the Python Essentials and can be downloaded from the Utilities menu in Statistics 22 or from the Extension Commands collection of the SPSS Community website (www.ibm.com/developerworks/spssdevcentral) Provides overall estimate of kappa, along with asymptotic standard error, Z statistic, significance or p value under the null hypothesis of chance agreement and confidence interval for kappa. (Standard errors are based on Fleiss et al., 1979 and Fleiss et al., 2003. Test statistic is based on Fleiss et al., 2003.) Also provides these statistics for individual categories, as well as conditional probabilities for categories, which according to Fleiss (1971, p. 381) are probabilities of a second object being assigned to a category given that the first object was assigned to that category. Jon Peck (no "h") aka Kim Senior Software Engineer, IBM [hidden email] phone: 720-342-5621 From: Max Jasper <[hidden email]> To: [hidden email], Date: 06/16/2014 08:33 AM Subject: Re: [SPSSX-L] inter-rater reliability with multiple raters Sent by: "SPSSX(r) Discussion" <[hidden email]> Check these out may help: ftp://ftp.boulder.ibm.com/software/analytics/spss/support/Stats/Docs/Statistics/Macros/Iccsf.htm Hi everyone! I need help with a research assignment. I'm new to IBM SPSS statistics, and actually statistics in general, so i'm pretty overwhelmed. My coworkers and I created a new observation scale to improve the concise transfer of information between nurses and other psychiatric staff. This scale is designed to facilitate clinical care and outcomes related research. Nurses and other staff members on our particular inpatient unit will use standard clinical observations to rate patient behaviors in eight categories ( 1. abnormal motor activity, 2. activities of daily living, 3. bizarre/disorganized behavior, 4. medication adherence, 5. aggression, 6. observation status, 7. participation in assessment, and 8. quality of social interactions). Each category will be given a score 0-4, and those ratings will be summed to create a a total rating. At least two nurses will rate each patient during each shift, morning and evening (so one patient should theoretically have at least four ratings per day). My assignment is to examine the reliability and validity of this new scale, and determine its utility for transfer of information. Right now I'm trying to figure out how to examine inter-rater reliability. IBM SPSS doesn't have a program to calculate Fleiss kappa (that I know of) and I'm not sure if that's what I should be calculating anyway...I'm confused because there are multiple raters, multiple patients, and multiple dates/times/shifts. The raters differ from day to day even on the same patient's chart, so there is a real lack of consistency in the data. Also sometimes only one rating is done on a shift...sometimes the nurses skip a shift of rating altogether. Also there are different lengths of stay for each patient, so the amount of data collected for each one differs dramatically. I've attached a screenshot of part of our unidentified data. Can anyone please help me figure out how to determine inter-rater reliability? (Or if anyone has any insight into how to determine validity, that'd be great too!) Thanks so much! |
|
|
In reply to this post by MaxJasper
Fleiss’ kappa was designed for nominal data. If your data are ordinal, interval, ratio, then use the ICC or other related procedure
for continuous data. The ICC provides analyses which have been found analogous to Fleiss’ weighted kappa (Fleiss and Cohen, 1973). The syntax that Max refers to looks like the most promising alternative, as long as you know what model you have. If you need
Fleiss’ kappa syntax because you have nominal data, I can send that to you offline. Brian From: SPSSX(r) Discussion [mailto: Check these out may help: ftp://ftp.boulder.ibm.com/software/analytics/spss/support/Stats/Docs/Statistics/Macros/Iccsf.htm Hi everyone! I need help with a research assignment. I'm new to IBM SPSS statistics, and actually statistics in general, so i'm pretty overwhelmed.
Nurses and other staff members on our particular inpatient unit will use standard clinical observations to rate patient behaviors in eight
categories (
1.
abnormal motor activity,
2.
activities of daily living,
3.
bizarre/disorganized behavior,
4.
medication adherence,
5.
aggression,
6.
observation status,
7.
participation in assessment, and
8.
quality of social interactions).
Each category will be given a
score 0-4, and those ratings will be summed to create a
a total rating. At least two nurses
will rate each patient during each shift, morning
and evening (so one patient should theoretically have at least four ratings per day).
|
|
|
An ICC to estimate interrater reliability can be calculated using the MIXED procedure in SPSS, and can handle various designs. I believe I have posted on this topic in the past for at least one scenario, perhaps two. Ryan On Mon, Jun 16, 2014 at 10:49 AM, Dates, Brian <[hidden email]> wrote:
|
Re: inter-rater reliability with multiple raters
|
|
Estimators of ICCs generally want "balanced designs", don't they?
Did you have an answer to that complication? - Another poster mention G-theory, and I would expect the same problem. I never used G-theory and what I read was long ago, but I don't remember the issue being dealt with. -- Rich Ulrich Date: Mon, 16 Jun 2014 11:11:44 -0400 From: [hidden email] Subject: Re: inter-rater reliability with multiple raters To: [hidden email] An ICC to estimate interrater reliability can be calculated using the MIXED procedure in SPSS, and can handle various designs. I believe I have posted on this topic in the past for at least one scenario, perhaps two. Ryan On Mon, Jun 16, 2014 at 10:49 AM, Dates, Brian <[hidden email]> wrote:
|
|
|
Okay. Let me start by saying I'm a bit (okay maybe very) under the weather and paid work is catching up with me, so apologies for any typos/mistakes. Having said that, this topic is quite interesting as it relates to showing some connections between generalizability coefficients, various forms of ICCs, and coefficient alpha.
Before discussing those connections, however, the short answer to the question about whether there are valid estimators of an ICC in an unbalanced design would be a solid "it depends." I would argue that to obtain a valid ICC we need to appropriately decompose the variance to obtain between subject variance and variance attributable to all other sources. This could prove challenging.
At any rate, if the raters tend to agree in their ratings of each subject, then the between subject variance will tend to be much larger than other sources of variances, and the ICC should approach 1.0.
With that said, the ICC is defined as: ICC = var(between Ss) / Total Variance where, Total Variance = (1) between Ss variance (2) between Rater Variance (3) error variance
If one initially planned a crossed design (all subjects were intended to be rated by all raters) but due to random circumstances some raters were unable to rate some subjects and those missing data can be assumed to be missing at random (MAR), then I would suggest that one could theoretically estimate a valid estimate of the ICC using an ML estimator via the MIXED procedure in SPSS from which the estimated variance components would be inserted into the following ICC equation:
ICC = var(between Ss )/ [var(between Ss) + error variance] I believe there are more sophisticated ways to deal with unbalanced designs that have been published in the past 5 years, but I am not fully versed in such methods. With that said, please see below for a small demonstration using SPSS syntax that might help make connections between generalizability coefficients from a one-facet design, ICC, and coefficient alpha using various procedures in SPSS:
DATA LIST LIST / rater1 rater2 rater3 (3f1.0). BEGIN DATA 3 4 4 1 2 3
4 4 5 7 6 10
1 2 3 END DATA. *Calculate ICC via Reliabillity Procedure: MIXED model with CONSISTENCY type.
RELIABILITY /VARIABLES=rater1 rater2 rater3 /SCALE('ALL VARIABLES') ALL /MODEL=ALPHA /ICC=MODEL(MIXED) TYPE(CONSISTENCY) CIN=95 TESTVAL=0.
*Calculate ICC via Reliabillity Procedure: RANDOM model with ABSOLUTE type. RELIABILITY /VARIABLES=rater1 rater2 rater3 /SCALE('ALL VARIABLES') ALL /MODEL=ALPHA
/ICC=MODEL(RANDOM) TYPE(ABSOLUTE) CIN=95 TESTVAL=0. *Restructure dataset from wide to long to more easily obtain variance components. VARSTOCASES /ID=id /MAKE rating FROM rater1 rater2 rater3
/INDEX=rater(3) /KEEP= /NULL=KEEP. MIXED rating BY id rater /FIXED=| SSTYPE(3) /METHOD=REML /RANDOM=id rater | COVTYPE(VC).
*ICC version where all subjects are rated by same/consistent random subset of all possible raters. *ICC matches the Single Measure ICC via Reliability Procedure: RANDOM model with ABSOLUTE type.
*Note: ICC_1 = var(between Ss) / [var(between Ss) + var(raters) + error]. COMPUTE ICC_1 = 5.200 / (5.200 + 0.767 + 0.633). EXECUTE. MIXED rating BY id rater /FIXED=rater| SSTYPE(3)
/METHOD=REML /RANDOM=id | COVTYPE(VC). *ICC version where subjects are rated by the assumed population of all possible raters. *Matches Single Measure ICC from Reliability Procedure.
*Note: ICC_2 = var(between Ss) / [var(between Ss) + error]. COMPUTE ICC_2= 5.200 / (5.200 + 0.633). EXECUTE. MIXED rating BY id rater /FIXED=| SSTYPE(3)
/METHOD=REML /RANDOM=id | COVTYPE(VC). *ICC version where subjects are assumed to be randomly assigned to a sample of raters, assuming a balanced design. *In the MIXED model above, note that rater is removed from the model entirely.
COMPUTE ICC_3 = 4.944 / (4.944 + 1.400). EXECUTE. *Next, let's employ a one-facet G theory model using ANOVA. DATASET DECLARE vc. VARCOMP rating BY rater id
/RANDOM=rater id /OUTFILE=VAREST (vc) /METHOD=SSTYPE(3) /PRINT=SS /DESIGN=rater id /INTERCEPT=INCLUDE. DATASET ACTIVATE vc.
*Using variance components estimated from the mean squares of the ANOVA above. *the relative and absolute G coefficients are estimated. *Note that the relative G coefficient = coefficient alpha.
*Note, also, ICC matches the average measure ICC via Reliability Procedure:. *RANDOM model with CONSISTENCY type. *VC1 = var(rater). *VC2 = var(subject). *VC3 = error variance.
*Based on the equation below, it becomes apparent that coefficient alpha assumes. *that between rater variance ("VC1") = zero. COMPUTE relative_g_coeff_3raters = VC2 / (VC2 + VC3/3).
*If we assume the number of raters is 1 (one), we obtain the. *ICC for single measures calculated from Reliability Procedure. *and the second MIXED procedure. COMPUTE relative_g_coeff_1rater = VC2 / (VC2 + VC3/1).
*Next, compute the absolute g coefficient assuming 3 raters. *Note: Also, ICC matches the average measure ICC via Reliability Procedure:. *RANDOM model with ABSOLUTE type.
COMPUTE absolute_g_coeff_3raters = VC2 / (VC1/3 + VC2 + VC3/3). *Next, compute the absolute g coefficient assuming 1 rater. *Note: Matches ICC estimated from first MIXED model which assumes.
*that subjects and raters are random. *Note: Also, ICC matches the single measure ICC via Reliability Procedure:. *RANDOM model with ABSOLUTE type. COMPUTE absolute_g_coeff_1rater = VC2 / (VC1/1 + VC2 + VC3/1).
EXECUTE. |
Re: inter-rater reliability with multiple raters
|
|
ICCs with unequal Ns - I got a reference in 1995 for computing a simple ICC with unequal Ns from the Usenet stats group, sci.stat.consult. I put the formula (below) in my stats-FAQ, which I maintained from 1997 to about 2006. No one ever provided newer references. This is owing to Ernest Haggard, Intraclass Correlation and the Analysis of Variance (1958) , as posted by Michael Bailey and reformatted and adapted by me. I hope I have not screwed it up. Let, R=intraclass correlation, BSMS=between Subject mean square, WMS=mean square within, c=number of Subjects, and ki=number for the ith Subject. Then: R = (BSMS - WMS) / ( BSMS + (k' -1)*WMS ) where k' = [ sum(ki) - (sum(ki**2))/sum(ki) ] / (c-1) The value of k' does need to work out to something in the range of an average ki number of ratings for the subjects. I think that I remember using the "reciprocal mean" of the counts, but I don't remember using this formula for k' for getting it. -- Rich Ulrich Date: Tue, 17 Jun 2014 22:49:46 -0400 From: [hidden email] Subject: Re: inter-rater reliability with multiple raters To: [hidden email] Okay. Let me start by saying I'm a bit (okay maybe very) under the weather and paid work is catching up with me, so apologies for any typos/mistakes. Having said that, this topic is quite interesting as it relates to showing some connections between generalizability coefficients, various forms of ICCs, and coefficient alpha. Before discussing those connections, however, the short answer to the question about whether there are valid estimators of an ICC in an unbalanced design would be a solid "it depends." I would argue that to obtain a valid ICC we need to appropriately decompose the variance to obtain between subject variance and variance attributable to all other sources. This could prove challenging.
At any rate, if the raters tend to agree in their ratings of each subject, then the between subject variance will tend to be much larger than other sources of variances, and the ICC should approach 1.0.
With that said, the ICC is defined as: ICC = var(between Ss) / Total Variance where, Total Variance = (1) between Ss variance (2) between Rater Variance (3) error variance
If one initially planned a crossed design (all subjects were intended to be rated by all raters) but due to random circumstances some raters were unable to rate some subjects and those missing data can be assumed to be missing at random (MAR), then I would suggest that one could theoretically estimate a valid estimate of the ICC using an ML estimator via the MIXED procedure in SPSS from which the estimated variance components would be inserted into the following ICC equation:
ICC = var(between Ss )/ [var(between Ss) + error variance] I believe there are more sophisticated ways to deal with unbalanced designs that have been published in the past 5 years, but I am not fully versed in such methods. With that said, please see below for a small demonstration using SPSS syntax that might help make connections between generalizability coefficients from a one-facet design, ICC, and coefficient alpha using various procedures in SPSS: [snip, SPSS code for alpha examples] |
|
|
Okay, I'm going to try that formula out on a small dataset and compare it to the mixed model (ML estimation) approach I suggested. More later. Sent from my iPhone
|
Re: inter-rater reliability with multiple raters
|
Administrator
|
In reply to this post by Rich Ulrich
Rich, do you still have all of the files for your FAQ? If so, someone really ought to get them back on a website somewhere.
--
Bruce Weaver bweaver@lakeheadu.ca http://sites.google.com/a/lakeheadu.ca/bweaver/ "When all else fails, RTFM." PLEASE NOTE THE FOLLOWING: 1. My Hotmail account is not monitored regularly. To send me an e-mail, please use the address shown above. 2. The SPSSX Discussion forum on Nabble is no longer linked to the SPSSX-L listserv administered by UGA (https://listserv.uga.edu/). |
Re: inter-rater reliability with multiple raters
|
|
Yes, I have them. Everything (old version, new version) is in a couple of
directories, with a fair amount of duplication, and with the same date of 3/29/2004. I think the proper content amounts to 150 files, 1.5 MB or so. I suppose that much disk space can be rented at trivial cost. I don't know how to go about doing that - who to use, etc. I just now realized how easy it would be to install them -- almost all the file links are relative to "this directory", so I can go to the indexing file and click on them right now. It could use some updating on some things. It became easier to Google than to use my own indexes, even when Google would point to my FAQ. And Google would give the more recent posts. I know that I have seen some better references cited on a number of topics since I stopped adding things in about 1998. And sometimes, some better comments. One initial approach might be, I could just insert comments *saying* that this can be improved. Then I would want an "Comments" section where people could submit suggestions. Or mail me old posts that make good points. Someone, want to give me advice about doing this? -- Rich Ulrich > Date: Wed, 18 Jun 2014 18:39:59 -0700 > From: [hidden email] > Subject: Re: inter-rater reliability with multiple raters > To: [hidden email] > > Rich, do you still have all of the files for your FAQ? If so, someone really > ought to get them back on a website somewhere. > [snip] |
|
|
Just a suggestion: a wiki(pedia) type website
might be a good
format. This would allow new information
to added easily as
well as maintaining some degree control over
content. One
source on this is the following:
Whether this is the best format will depend
upon the resources
you have available (e.g., time, whether you
can get free hosting,
colleagues to act as
editors/admins).
-Mike Palij
New York University
|
Re: inter-rater reliability with multiple raters
|
Administrator
|
In reply to this post by Rich Ulrich
The current version of my stats web-pages was set up via Google Sites (https://sites.google.com/a/lakeheadu.ca/bweaver/Home/statistics). I moved (most) things there (from Angelfire) when my university started using a version of Gmail. As part of the new e-mail system, each user could set up a personal website. I've never had a "regular" Gmail account, but would guess that users of those accounts also have access to Google Sites. So that would be one option to consider.
If John Hall is reading this, maybe he can chip in with his thoughts about the "weebly" site where his survey analysis workshop is housed (http://surveyresearch.weebly.com/1-survey-analysis-workshop.html). And there's wordpress.com, where Andy has his site (http://andrewpwheeler.wordpress.com/). There are a few, for a start.
--
Bruce Weaver bweaver@lakeheadu.ca http://sites.google.com/a/lakeheadu.ca/bweaver/ "When all else fails, RTFM." PLEASE NOTE THE FOLLOWING: 1. My Hotmail account is not monitored regularly. To send me an e-mail, please use the address shown above. 2. The SPSSX Discussion forum on Nabble is no longer linked to the SPSSX-L listserv administered by UGA (https://listserv.uga.edu/). |
|
|
I use Wordpress + Dropbox. A very simple solution (no programming required) is to just save the files via Dropbox, and then use Wordpress (or any blogging platform) as a front page to point to the files with a bit of organization. Dropbox is free for smaller file sizes (but at this point I pay a subscription and back everything up with it) and Wordpress is free as well (unless you want to buy your own domain name).
If you are just posting text snippets of code - sharing Dropbox links will be fine. If you are uploading large data files though it can become problematic because (in the free version) they throttle your downloads after so many megabytes. If you want something nicer looking it will take more work, but that is my minimal and free suggestion to anyone starting out. The wiki suggestion by Mike is interesting as well - Wordpress you can have multiple editors so it can be wiki like. Dropbox has a system like this is as well but I have not used it. Post back to the list Rich when you get a site up. I should probably add this to my blog, but I basically set up the tag wiki on the CrossValidated site for my suggested SPSS references, http://stats.stackexchange.com/tags/spss/info. |
|
|
In reply to this post by Mike
I've just been contracted to set up a learning community around performance measurement/management. We've set up a Google Blog, and we're attaching our files for upload on a Google
Drive. I'm offering that as something to investigate...and also asking for feedback on how pedestrian it might be. I should be finished with my edit of the monograph on interrater agreement for nominal scales in the next two weeks, including the edits of
all the syntax. I'm trying to find a suitable place to post the info so listserv members can access it. Marta Garcia Granero set up a website for her contributions, I believe, so maybe that's the way to go??
Brian
From: SPSSX(r) Discussion [[hidden email]] on behalf of Mike Palij [[hidden email]]
Sent: Thursday, June 19, 2014 7:24 AM To: [hidden email] Subject: Re: inter-rater reliability with multiple raters Just a suggestion: a wiki(pedia) type website might be a good
format. This would allow new information to added easily as
well as maintaining some degree control over content. One
source on this is the following:
Whether this is the best format will depend upon the resources
you have available (e.g., time, whether you can get free hosting,
colleagues to act as editors/admins).
-Mike Palij
New York University
|
|
|
In reply to this post by Rich Ulrich
The linear MIXED modeling (LMM) procedure is a preferred approach to estimating parameters using REML for unbalanced designs where the data are assumed to be missing at random (MAR). Consistent with the underlying theory of LMM, I have generated data below for which the number of ratings per subject varies according to a random uniform variate. I then estimate the between subject variance and residual variance using the default REML estimation method offered by the MIXED procedure, which is all that is needed to calculate an ICC.
=====================
To manage your subscription to SPSSX-L, send a message to
[hidden email] (not to SPSSX-L), with no body text except the
command. To leave the list, send the command
SIGNOFF SPSSX-L
For a list of commands to manage subscriptions, send the command
INFO REFCARD
It should be noted that the linear MIXED model I have employed conforms to one way of estimating an ICC for a specific design described by: Shrout, P.E. and Fleiss, J.L (1979). Intraclass correlations: uses in assessing rater reliability. Psychological Bulletin, 86, 420-428
where, 1. Each subject is rated by multiple raters 2. Raters are assumed to be randomly assigned to subjects 3. All subjects have the same number of raters
Note that this is consistent with one of the examples in my previous post: The data generated below conform to 1. and 2., but obviously not 3. However, as I mentioned before, as long as the data are MAR, the REML estimators should reasonably recover the parameters. Using the example below, the population between subjects VC = .300 and the population ICC=.231. The MIXED model estimates the VC = .306 and the estimated ICC = 0.230.
Note: I generated data that do not specify which raters were assigned to each subject. This post is not intended to compare the proposed method to other methods, but simply to provide a concrete example of how one might estimate an ICC where each subject has been rated by a varying random number of raters.
Ryan -- /*Generate Data*/. SET SEED 987879546. NEW FILE. INPUT PROGRAM. COMPUTE subject_ID = -99. COMPUTE intercept= -99.
COMPUTE nobs = -99. LEAVE subject_ID to nobs. LOOP subject_ID = 1 to 100. COMPUTE intercept = sqrt(.30)*rv.normal(0,1). COMPUTE nobs = rnd(rv.uniform(12,35)). LOOP j=1 to nobs.
COMPUTE y = intercept + rv.normal(0,1). END CASE. END LOOP. END LOOP. END FILE. END INPUT PROGRAM. EXECUTE. *Fit Linear Mixed Model.
MIXED y BY subject_ID /FIXED= | SSTYPE(3) /METHOD=REML /PRINT= G /RANDOM=subject_ID. *Estimate ICC. COMPUTE ICC =.30628546692761 / (.30628546692761 + 1.02273871556984 ).
EXECUTE. On Wed, Jun 18, 2014 at 12:48 PM, Rich Ulrich <[hidden email]> wrote:
|
| Free forum by Nabble | Edit this page |