restructuring data file


|
Hi all: I am looking for an automated way to restructure a data file. Right now the data file looks like the following with 3 sample variables (ID, time, dv): ID time dv 1 1 8 1 1 8 1 2 4 1 2 4 There are varying number of time-points throughout the data file (i.e., not only two as I have presented above). Here is the issue. There are redundant rows of data. I would simply like to remove the 2nd and 4th row from the sample data file above. Any ideas? |
|
Administrator
|
AGGREGATE OUTFILE * / BREAK ALL / count=N.
/* DELETE VARIABLES count. --
Please reply to the list and not to my personal email.
Those desiring my consulting or training services please feel free to email me. --- "Nolite dare sanctum canibus neque mittatis margaritas vestras ante porcos ne forte conculcent eas pedibus suis." Cum es damnatorum possederunt porcos iens ut salire off sanguinum cliff in abyssum?" |
|
Administrator
|
Very nice! For those who do not have SPSS installed, here is result of David's AGGREGATE (using Scott's sample data shown below):
ID time dv count 1 1 8 2 1 2 4 2 Number of cases read: 2 Number of cases listed: 2
--
Bruce Weaver bweaver@lakeheadu.ca http://sites.google.com/a/lakeheadu.ca/bweaver/ "When all else fails, RTFM." PLEASE NOTE THE FOLLOWING: 1. My Hotmail account is not monitored regularly. To send me an e-mail, please use the address shown above. 2. The SPSSX Discussion forum on Nabble is no longer linked to the SPSSX-L listserv administered by UGA (https://listserv.uga.edu/). |
|
|
In reply to this post by Scott Roesch
Data > Identify Duplicate Cases gives
you a lot of options on exactly what to do.
Jon Peck (no "h") aka Kim Senior Software Engineer, IBM [hidden email] phone: 720-342-5621 From: Scott Roesch <[hidden email]> To: [hidden email] Date: 07/03/2015 08:29 AM Subject: [SPSSX-L] restructuring data file Sent by: "SPSSX(r) Discussion" <[hidden email]> Hi all: I am looking for an automated way to restructure a data file. Right now the data file looks like the following with 3 sample variables (ID, time, dv): ID time dv 1 1 8 1 1 8 1 2 4 1 2 4 There are varying number of time-points throughout the data file (i.e., not only two as I have presented above). Here is the issue. There are redundant rows of data. I would simply like to remove the 2nd and 4th row from the sample data file above. Any ideas? ===================== To manage your subscription to SPSSX-L, send a message to LISTSERV@... (not to SPSSX-L), with no body text except the command. To leave the list, send the command SIGNOFF SPSSX-L For a list of commands to manage subscriptions, send the command INFO REFCARD ===================== To manage your subscription to SPSSX-L, send a message to [hidden email] (not to SPSSX-L), with no body text except the command. To leave the list, send the command SIGNOFF SPSSX-L For a list of commands to manage subscriptions, send the command INFO REFCARD |
|
Administrator
|
But that AGG solution is so simple in comparison to the paste from the identify DUP cases ;-) On Jul 3, 2015 12:32 PM, "Jon K Peck [via SPSSX Discussion]" <[hidden email]> wrote:
Data > Identify Duplicate Cases gives you a lot of options on exactly what to do.
Please reply to the list and not to my personal email.
Those desiring my consulting or training services please feel free to email me. --- "Nolite dare sanctum canibus neque mittatis margaritas vestras ante porcos ne forte conculcent eas pedibus suis." Cum es damnatorum possederunt porcos iens ut salire off sanguinum cliff in abyssum?" |
|
|
This post was updated on .
In reply to this post by David Marso
Hi David,
I was wondering whether you know a syntax that would allow to rapidly fill the cells in my SPSS database when I have Level 2 variables ? Usually, when I have Level 2 variables, I enter all the data "manually", which takes forever. For instance, let's say my variables are organized as depicted below in my database, is there code/syntax so that SPSS could automatically fill in the empty cells for all the Level 2 units ? Thanks in advance for your help ! O. 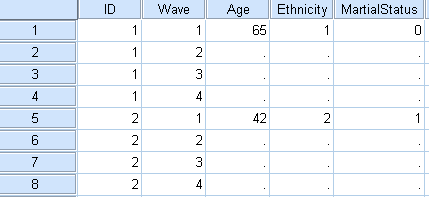 |
|
Administrator
|
Something like this (untested) will fill in the missing cells.
DO REPEAT v = Age to MaritalStatus. - IF MISSING(v) v = LAG(v) END REPEAT. DESCRIPTIVES Age to MaritalStatus. But if you generated that dataset by merging a level 1 file with a level 2 file via MATCH FILES, look up the difference between /FILE and /TABLE, and study some examples. If you use /TABLE appropriately when merging the two files, there will be no missing cells to fill in. See Example 3 here: http://www.ats.ucla.edu/stat/spss/modules/merge.htm. HTH.
--
Bruce Weaver bweaver@lakeheadu.ca http://sites.google.com/a/lakeheadu.ca/bweaver/ "When all else fails, RTFM." PLEASE NOTE THE FOLLOWING: 1. My Hotmail account is not monitored regularly. To send me an e-mail, please use the address shown above. 2. The SPSSX Discussion forum on Nabble is no longer linked to the SPSSX-L listserv administered by UGA (https://listserv.uga.edu/). |

|
|
Hi Bruce, Thanks for trying to solve my problem. When I try the syntax you proposed, I do get the following error message from SPSS (see picture attached). Any way I could modify the syntax in order to make it work ? Thanks in advance, MO. 
|
|
Administrator
|
Missing period on the IF statement.
Please post your exact syntax next time. Q
Please reply to the list and not to my personal email.
Those desiring my consulting or training services please feel free to email me. --- "Nolite dare sanctum canibus neque mittatis margaritas vestras ante porcos ne forte conculcent eas pedibus suis." Cum es damnatorum possederunt porcos iens ut salire off sanguinum cliff in abyssum?" |

|
|
David & Bruce, Thank you so much for your help. The syntax below works perfectly and allows to copy/paste Level 2 data, within each ID, across all IDs included in the database. This will allow me to save hours and hours of work. DO REPEAT v = Age to MaritalStatus. - IF MISSING(v) v = LAG(v). END REPEAT. DESCRIPTIVES Age to MaritalStatus. **For those reading this message, please refer to my earlier post in order to understand the name of variables (i.e., Age, MaritalStatus) included in this syntax. O. |
«
Return to SPSSX Discussion
|
1 view|%1 views
| Free forum by Nabble | Edit this page |